Pareciera que cualquier paisaje crece en inmensidad al llegar el arrebol. Ese momento en el cual realmente la naturaleza se alinea para revelar colores secretos.
Siempre llamaron mi atención. Había notalidades y colores que no se veían en ningún otros lugares. Nubes rojas como fuego, nubes largas de color naranjo fosforescente, y hastas a veces se veían arcoiris en las nubes producto de la iridiscencia. Siempre quería fotografiarlas y aprendí a leer las nubes.
Con esto en mente escribí Préboles: aplicación que estima la probabilidad de arrebol dadas las coordenadas.
Versión 1. (21/12/2025)
Modelo básico de Predicción de arreboles
Para describir el arrebol con un modelo probabilistico, primero hay que asumir que el fenómeno arrebol es binario, es decir, puede haber arrebol, o no haber arrebol.
Para que exista un arrebol, hay ciertas variables atmosféricas que deben coincidir desde donde el observador contemplará el fenómeno, como por ejemplo la presencia o falta de algunas nubes o la visibilidad hacia la dirección del sol.
Entonces, necesitamos un estadístico que pueda describir la probabilidad de ocurrencia (ocurre/no ocurre, verdadero/falso, 0/1, etc) de un fenómeno dada la información que tenemos sobre él. Esta es (casi) la definición de una regresión logística. Básicamente es una regresión normal (la suma ponderada de la información disponible), la unidad base de las redes neuronales clásicas. La regresión logística se define de la siguiente forma:
donde la probabilidad es un numero real, y está contenida en el intervalo $0<p(\vec{x})<1$. La probabilidad depende del vector $\vec{x}=(x_1, x_2, \cdots, x_n)$, el cual contiene la información que hemos recolectado del arrebol, y $f(\vec{x})$ es una función lineal que depende de la información del fenómeno. Si definimos $f(\vec{x})$ de la forma:
donde el set de valores $\beta_i =\{ \beta_0,\beta_1,...\beta_n \}$ es un arreglo de $n+1$ pesos o factores ponderantes del vecto de características $\vec{x}$. Considerando notación vectorial:
es decir, si determinamos los $n+1$ parámetros o pesos $\vec{\beta}$, podremos obtener la contribución de cada factor climático (o características) $\vec{x}$ por las cuales ocurre un arrebol. Si tenemos todo lo anterior, una predicción podría ser realizada.
¿Cómo obtener el set de valores $\beta_i$? Éstos pueden ser obtenidos a través de métodos de ajustes estádisticos (como míminos cuadrados o métodos de máxima verosimilitud) si tenemos una base de datos con la qué consultar.
Sobre el vector de características
Una vez establecido el modelo probabilístico básico $p(\vec{x})$, es necesario definir las componentes del vector de características $\vec{x}$ y el método para obtener el valor de predicción $S$ a partir de datos meteorológicos disponibles.
El vector $\vec{x}$ se construye como una combinación lineal ponderada de $n=4$ factores atmosféricos básicos, cada uno normalizado al intervalo $[0,1]$.
En general, las contribuciones de las diferentes variables serán modeladas a traves de una función gaussiana. Los parámetros considerados para la predicción de arreboles son:
Porcentaje de cielo cubierto de nubes
Hay tres tipos principales de nubes: Nubes bajas, nubes medias y nubes altas. La probabilidad del arrebol es proporcional a la altura de las nubes. Entonces, si llamamos $F_N$ al factor de contribución de las nubes altas $N_{altas}$, las nubes medias $N_{medias}$ y $N_{baja}$, la contribuciòn total de las nubes es de la forma:
donde los factores de nubes se acompañan de un factor ponderante calibrado en base a experiencia y divido 100 para su normalización.
Factor geométrico de nubes
Las nubes generan el arrebol dada la configuración geométrica de los rayos del sol, al iniciaro o terminar el día. Existen distinciones bien definidas para la altura del sol luego del amanecer/atardecer, ambos se diferencian en el ángulo de inclinación del sol con respecto al horizonte visible: existe el "crepúsculo civil" ($-6^\circ<\theta<0^\circ$) y el "crepúsculo nautico" ($-12^\circ<\theta<-6^\circ$). Para determinar la contribución $F_{\theta}$ del factor geométrico, podemos modelar la dependencia del arrebol con el ángulo $\theta$ de inclinación del sol mediante una función de decaimiento gaussiano:
$$
F_{\theta} = \exp\left[-\left(\dfrac{ -|\theta|- \theta_{ideal}}{\sigma_\theta}\right)^2\right],
$$
donde $\theta_{ideal}$ es el ángulo más probable que produzca arrebol, lo consideraremos como $\theta_{ideal}=-3^\circ$, que es el punto medio del crepusculo civil, y $\sigma_\theta = 4^\circ$, el cual integra el intervalo. Este factor geométrico actua como un "interruptor" o filtro para que no exista probabilidad de arrebol en configuraciones donde físicamente no es posible.
Dispersión de Rayleigh y la presión Atmosférica
La presión atmosférica afecta la dispersión de la luz, modificando la densidad del aire (mayor presión, mayor densidad de particulas para dispersar luz). También, los sistemas de alta presión tienden a tener cielos más despejados con nubes altas y delgadas.
La intensidad de dispersión Rayleigh $I_R$ para una longitud de onda $\lambda$ está dada por:
donde $I_0$ es la intensidad de la luz solar, $\alpha = \frac{n^2 - 1}{n^2 + 2}$ es la posible polarización molecular, $n$ el índice de refracción del aire, $\lambda$ es la longuitud de onda, $R$ la distancia al observador, $\theta$ es el ángulo de dispersión, y $\rho$ es la densidad atmosférica. Varios de los parámetros presentes en la expresión pueden considerarse aproximadamente constantes ($\lambda$ pertenece siempre al rango visible, $n$ y $\theta$ presentan variaciones pequeñas) bajo condiciones atmosféricas normales. Además, si asumimos que $\rho \sim P$, la contribución de la dispersión de Rayleigh puede resepresntarse como una ley de potencias de la forma:
donde $P_0 = 1013hPa$ (hectopascal) es la presión de referencia a nivel del mar, y $\gamma$ podría ser considerado la unidad para un gas ideal a temperatura $T$ constante.
Normalizada entre 0 y 1 para $P \in [P_0, P_{max}]$:
$$
F_{Rayleigh} = \frac{\left( \dfrac{P}{P_0} \right)^{\gamma} - 1}{\left( \dfrac{P_{max}}{P_0} \right)^{\gamma} - 1}
$$
Nota: Por favor no usar lo anterior de ninguna forma como referencia. Asumí demasiadas cosas que habría que revisar bien si son ciertas o no. Sólo asumí para seguir avanzando.
Humedad
En condiciones de humedad baja, las partículas permanecen pequeñas y la dispersión es limitada, lo que suele producir diferentes tonalidades de color. A medida que la humedad aumenta, las partículas absorben vapor de agua, crecen en tamaño y podrían dispersan la luz roja a mayor tasa, generando arreboles intensos. Pero mucha humedad produce absorción reducen el contraste. Por eso, la contribución de la humedad es modelada por una gaussiana de la forma:
donde $H^{ideal}$ es la humedad relativa del 60%, y $\sigma_H = 20$%
Con respecto a las ponderaciones, para este modelo los pesos $\vec{\beta}$ se han calibrado empíricamente con la observaciòn y con datos históricos (Haciendo), resultando en la siguiente asignación de importancia relativa para la primera versión de Préboles
Pesos de los Factores:
Factor
Símbolo
Peso
Nubosidad por capas
$F_N$
50%
Geometría solar
$F_{\theta}$
20%
Presión/Rayleigh
$F_{Rayleigh}$
10%
Humedad atmosférica
$F_H$
10%
El término $\beta_0$ actúa como un umbral de calibración general.
Open-meteo es una base de datos libre que recolecta información meteorológica desde diferentes fuentes, donde dichas variables atmosféricas pueden ser accedidas dadas las coordenadas del planeta en donde querramos consultar. Particularmente, ofrece una grilla de datos de $11\times11$ $km^2$ donde recolecta datos en tiempo real, y también ofrece una predicción de las mismas variables en un futuro cercano. Entre otras variables, Open-meteo ofrece información sobre la distribución de las nubes (altas, medias, bajas), presión atmosférica, temperatura y otros datos (también históricos) que podrían ser relevantes.
Configuración geométrica del arrebol:
Básicamente el arrebol se genera porque los rayos del sol rebotan en las nubes y llegan hasta nuestros ojos. Es necesario tener en cuenta la geometría de la posición del sol y de las nubes para tener en cuenta la hora
Sobre la visualización de datos
Con todo lo anterior, se realiza la predicción del arrebol para diferentes ciudades y observatorios de Chile.
Mapa de probabilidad: Se utiliza como base la grilla de open-meteo, y luego se teselan hexágonos alrededor de la ciudad para mostrar la probabilidad que, desde allí, se pueda ver el arrebol tanto para el amanecer, como para el atardecer.
Series de tiempo de nubes: Como el modelo pondera fuertemente la presencia de nubes, las series de tiempo de porcentaje de nubes bajas, medias y altas son mostradas como referencia. También se agregan los momentos cuando ocurre el amanecer, el atardecer y la hora actual.
Validación y Mejoras Futuras
Redes sociales y reportes diarios.
Agregar Observatorios en Chile.
Calcular explícitamente a qué hora ocurre el arrebol.
Hace un tiempo pedí un Uber, abordé el automóvil y el altavoz menciona que yo iba en dirección al departamento de videojuegos de la Universidad de Talca. La persona que manejaba se sorprendió y me preguntó qué iba a hacer ahí. Le dije que era científico y que tenía que hacer clases de física.
-¿Y dónde está la física en el día a día?- Me pregunta de vuelta luego de algunos segundos. Una sencilla pregunta me llevó a un colapso de ideas, tantas posibles respuestas y debía ajustarse a la situación el la que estaba.
La persona esperaba atenta la respuesta, mientras calculaba con naturalidad la trayectoria y velocidad de cada automóvil en el camino, mientras en su teléfono se activaban y desactivaba miles de millones de transistores en cada interacción con la pantalla, mientras los satélites en órbita recibían las señales y triangulaban con una exactitud ridícula nuestra posición en el mapa.
Mientras todo esto pasaba, entendí que el mayor logro de la física (y de las ciencias en general) es la forma implícita en la puede afectar a las personas: ya no es necesario saber con completo detalles de qué trata para poder manipular la realidad en la que estamos. Las máquinas y aparatos tecnológicos actúan en base a una especie de magia, en realidad no importa cómo, lo importante es que realice su función.
-Tal ha sido el éxito de las ciencias que están en todas partes, tanto así que no somos consientes de su presencia.- Repliqué y traté de explicar, en un tiempo reducido y ojalá de una forma amena,
-ahh- Creo que alcancé a escuchar cuando dobló por 4 norte 1/2.
Verán, este es un tema recurrente cuando conozco a alguien y comento que soy astrónomo, las preguntas que surgen rara vez son novedosas. Una de ellas, y la más frecuente es: ¿Para qué sirve la astronomía? La segunda pregunta es (por si quieren saber) si existen los OVNIS. Entonces, hablemos un poco sobre cómo la astronomía ha influido en nuestras ciudades.
La astronomía está en el origen de la humanidad, en los cimientos de toda nuestra vida. Cada pueblo originario que se enfrentó a la abrumadora realidad tuvo que realizar esfuerzos mentales gigantescos para poder explicar la vida, encajar los eventos naturales en este relato y crear cohesión entre todos los eventos que eran presenciados (terremotos, tormentas, volcanes, tornados, cometas, etc). Los cazadores recolectores dependían completamente de su conocimiento de la realidad para poder sobrevivir, y esto incluía observar el cosmos con mucha detención para saber qué comer y dónde encontrarlo.
El hecho de ver todos los días el sol una y otra y otra vez daba luces de una propiedad fundamental de la naturaleza: La periodicidad. Parecía que el sol y ciertas estrellas estaban más bajas en tiempos de lluvia y más altas cuando las flores llegaban, y observando las estrellas comprendieron que la tierra estaba en un ciclo que se repetía constantemente.
Es que asumir que un ciclo se volverá a repetir trae grandes beneficios: Si asumimos que los días se repetirán uno tras otro tras otro sin pausa ni averías, tendremos calendarios, tendremos cultivos, tendremos puntos de referencia para poder emprender viajes. Tendremos ciudades con ritmos de vida frenéticos y personas con rutinas bien definidas, en función del horario en el que suceda este increíble fenómeno físico llamado “órbita”.
Varias culturas meso americanas sabían que el cielo era cíclico: en cierto periodo de tiempo el sol volvía a salir tras las mismas montañas y se escondía en el mar en función de la altura que alcanzaba. Los Incas, por ejemplo, usando las llamadas “saywas”(1) para definir el intervalo de tiempo entre que el sol sale por el mismo lugar a través de los solsticios. Al considerar esta observación, los incas mezclaron las ideas del espacio y el tiempo, con el fin de planificar el futuro (¿predecir el futuro?) y crear la capital de Sudamérica.
La astronomía, que en un principio nació bajo el alero de la curiosidad, no solo nos enseñó a entender el cielo; también nos ayudó a organizar los periodos de vida en la Tierra. Al observar las estrellas y encontrar patrones, se desarrollaros herramientas para medir el tiempo. Fundamental.
En la actualidad, muchos de los avances tecnológicos que damos por sentado tienen sus raíces en los desafíos de estudiar el cosmos. Galileo usó el Catalejo, en ese entonces un arma de guerra, para realizar una locura y mirar las estrellas, encontrando realidades inquietantes. Los edificios y los puentes usan las Leyes de Newton para equilibrar sus fuerzas y con eso impedir la dinámica y el colapso. Pero Isaac Newton no estaba pensando en edificios al diseñar sus famosas ecuaciones, sino que su mente buscaba una explicación a la orbita de la luna.
¿Cómo observamos galaxias a millones de años luz? Con telescopios y detectores que han llevado la óptica, la electrónica y el análisis de datos a niveles que sólo la ciencia ficción lograba dilucidar. ¿Cómo entendemos el Big Bang? Con satélites y antenas que fueron perfeccionadas estudiando la radiación de fondo de micro-ondas para luego ser usadas en las comunicaciones inalámbricas que hoy conectan cada dispositivos.
Los algoritmos que ajustan y describen las imágenes astronómicas son los mismos que ahora mejoran las imágenes médicas, influyendo en la salud de las personas. Incluso la necesidad de analizar enormes cantidades de datos para estudiar nuestra vecindad solar ha impulsado la evolución del Big Data y la inteligencia artificial, dos herramientas clave en áreas como la predicción climática, el desarrollo urbano, sólo por mencionar algunos.
Cada avance astronómico, por distante que parezca de la vida cotidiana, tiene una forma de regresar a nosotros gracias a la transferencia tecnológica, en aplicaciones que transforman la realidad, aquí y ahora. San Fernando ya nos ha enseñado sobre cómo es posible la comunicación global a través del Ingeniero Santiago Astraín, y sólo es cosa de tiempo para que todas las ciudades nos enseñen algo sobre las estrellas.
El verdadero secreto del cosmos es que puede ser entendido. Las estrellas, las montañas y las ciudades hablan y la realidad puede ser cuantificada a través de las matemáticas: el idioma del cosmos.
La ciencia es, en su esencia, la búsqueda de patrones. A lo largo de la historia, hemos aprendido a reconocer estos patrones en todo lo que nos rodea, desde nuestro pulso hasta la órbitas de las estrellas alrededor de agujeros negros. Uno de los patrones más fundamentales y omnipresentes en la naturaleza es la periodicidad. Entender cómo y por qué algo se repite de manera regular nos permite no solo describir fenómenos naturales, sino también predecirlos.
Es que "asumir" que un ciclo se volverá a repetir trae grandes beneficios: Si asumimos que los días se repetiran uno tras otro tras otro sin pausa ni averías, tendremos ciudades con ritmos de vida frenéticos y personas con rutinas bien definidas, en función del horario en el que suceda este increible fenómeno físico llamado "órbita".
Este concepto de periodicidad es clave en muchos campos de la ciencias, y sin dudas la astronomía es uno de esos campos. Las estrellas, que desde la antigüedad han sido observadas como puntos de luz fijos en el cielo, en realidad nos envían señales que varían con el tiempo. Entre todos los tipos de variaciones que estas estrellas pueden experimentar, existen el cambio de brillo periódico, y su luz puede ser analizada para obtener información sobre la física de dicha estrella, su composición, su ciclo de vida, etc. Dicho de otra forma: hasta a las estrellas es posible robarle uno y que otro secreto.
¿Cómo cuantificamos la periodicidad de algo? Bueno, decimos que la función que depende del tiempo $f(t)$, que podría describir es periódica si existe un número positivo $P$, llamado período, tal que:
$$
f(t) = f(t + P) \quad \text{para cualquier tiempo } t.
$$
Es decir, que la función $f(t)$ cíclicamente va cambiando su valor y luego de un tiempo $P$ retoma su valor inicial, y así el ciclo se vuelve a repetir. Por ejemplo, pensemos en el "ritmo cardiaco": Cuando mides tu pulso, hay que medir cuántas veces se siente el pulso en un rango de tiempo de un minuto, para cuantificar los "latidos por minuto" o "pulsos por minuto" (ppm). Si consideramos que el pulso cambia repetitivamente en un periodo de tiempo, podemos describir la frecuencia cardiaca como una función que depende del tiempo $f(t)$. Entonces, bastaría medir la función en varios instantes $t$ para poder determinar esta frecuencia cardiaca.
Si consideramos a una persona quieta que está sentada y con un reloj de medición puesto, con un ppm=70 [pulsos/minuto] (es decir, que su corazón late 70 veces por minuto, que su latido dura un poco menos de un segundo), la medición de su frecuencia cardiaca se verá más o menos de la siguiente forma:
importnumpyasnpimportmatplotlib.pyplotaspltplt.style.use('dark_background')#Tamanos de las letras y puntosfz=10ms=4# Parámetros para la simulación de la señal de frecuencia cardíacafs=50# Frecuencia de muestreo en Hzt=np.arange(0,5,1/fs)# Frecuencia cardíaca promedio en pulsos por minutofrecuencia_cardiaca_ppm=70.# Convertir PPM (Pulsos Por Minuto) a Hz (pulsos por segundo)frecuencia_hz=frecuencia_cardiaca_ppm/60.# Generar la señal de frecuencia cardíaca (señal sintética tipo ECG)senal_frecuencia_cardiaca=np.sin(2*np.pi*frecuencia_hz*t)+0.5*np.sin(4*np.pi*frecuencia_hz*t)# Agregamos ruido senal_frecuencia_cardiaca+=0.2*np.random.randn(len(t))plt.figure(figsize=(5,2))plt.plot(t,senal_frecuencia_cardiaca,'o',ms=ms-2)plt.title("Señal de frecuencia cardíaca simulada, con f = 1.116 [Hz]",fontsize=fz)plt.xlabel("Tiempo [s]",fontsize=fz)plt.ylabel("Amplitud normalizada",fontsize=fz-3)plt.grid(color='gray')# Ajustar el diseño de la gráficaplt.tight_layout()# Mostrar la gráficaplt.show()
Podemos ver las subidas y bajadas de una señal periodica (o sea, que se repite en el tiempo), y al ojo podríamos estimar (contando el tiempo que separa máximos o mínimos consecutivos) que su periodo es alrededor de 0.9 segundos. Es decir, la función frecuencia cardiaca se vuelve a repetir en un periodo definido.
En este caso es posible saber cuál es periodo exacto de la señal simulada, dado que el periodo es el recíproco de los pulsos por segundo (o frecuencia [Hz]), de la forma:
Determinado el periodo de una serie de tiempo, comienza lo interesante dado que podemos suponer cosas.
Como esta señal es periodica, significa que se está mapeando un proceso una y otra y otra vez a través del tiempo. Entonces, podríamos considerar todos los pulsos independientes y agruparlos sobre su periodo, con el fin de que la señal nos hable más sobre el procesos en cuestión. Este proceso se llama "doblado de fase" y asume que todos los ciclos de la señal son producto del mismo proceso sin cambios significativos.
La fase $\phi$ de una señal periódica describe la posición en el ciclo de la señal en un momento dado. Para calcular la fase de un fenómeno periódico se utiliza la expresión:
donde $int()$ es la parte entera del argumento. Es decir, reducimos a un espacio entre 0 y 1, donde cada ciclo mapea el proceso en cuestión a través de sus números decimales. En la práctica se usa la función módulo "%" para calcular el resto, pero ahora lo haremos siguiendo la definición con fines ilustrativos.
pulso=0.857#Segundos#Calculamos la fase a lo largo del tiempo:fase=np.array([(t[i]/pulso-int(t[i]/pulso))foriinrange(len(t))])#Ordenamos la señal en función de la fasesort=np.array([(senal_frecuencia_cardiaca[j],fase[j])forjinrange(len(t))])sort=sort[np.argsort(sort[:,1])]fase=sort[:,1]senal_frec_ordenada=sort[:,0]plt.figure(figsize=(5,3))plt.plot(fase,senal_frec_ordenada,'.',ms=ms)plt.title("Señal de frecuencia cardíaca con P=0.857 [s]",fontsize=fz)plt.xlabel("Espacio de fase $\phi$",fontsize=fz)plt.ylabel("Amplitud normalizada",fontsize=fz)plt.tight_layout()plt.show()
Si una señal tiene un comportamiento periódico, es conveniente describirla en términos de su "espacio de fase", nombre que se le da al gráfico entre el parámetro en cuestión y la fase $\phi$, desde donde podremos interpretar la forma de su ciclo, y qué parámetros podrían influir en su forma. En astrofísica, medir este tipo de pulsos puede hablarnos sobre la densidad de los objetos, sobre el mecanismo físico detrás de esta señal
Señales desde las estrellas
Imagina que estás observando una estrella que cambia su brillo de forma periódica. Si realizaras fotometría a sus observaciones, medirías el cambio de luminosidad en el tiempo, es posible obtiene una señal periodica en formato de serie de tiempo $\{x_n\}$. Es decir, una colección de observaciones de cierto suceso que ocurre en el cielo.
En astronomía este concepto se adapta para analizar la evolución temporal del brillo de las estrellas (galaxias también pero es más complejo). En general, para cada estrella conocida existe una serie de tiempo $\{x_n\}$ que es posible estudiar y determinar qué eventos ocurren en dicha estrella. Entonces, en nuestro caso, asumiendo que podría existir un periodo sus series de tiempo son escudriñadas para encontrar dichos periodos.
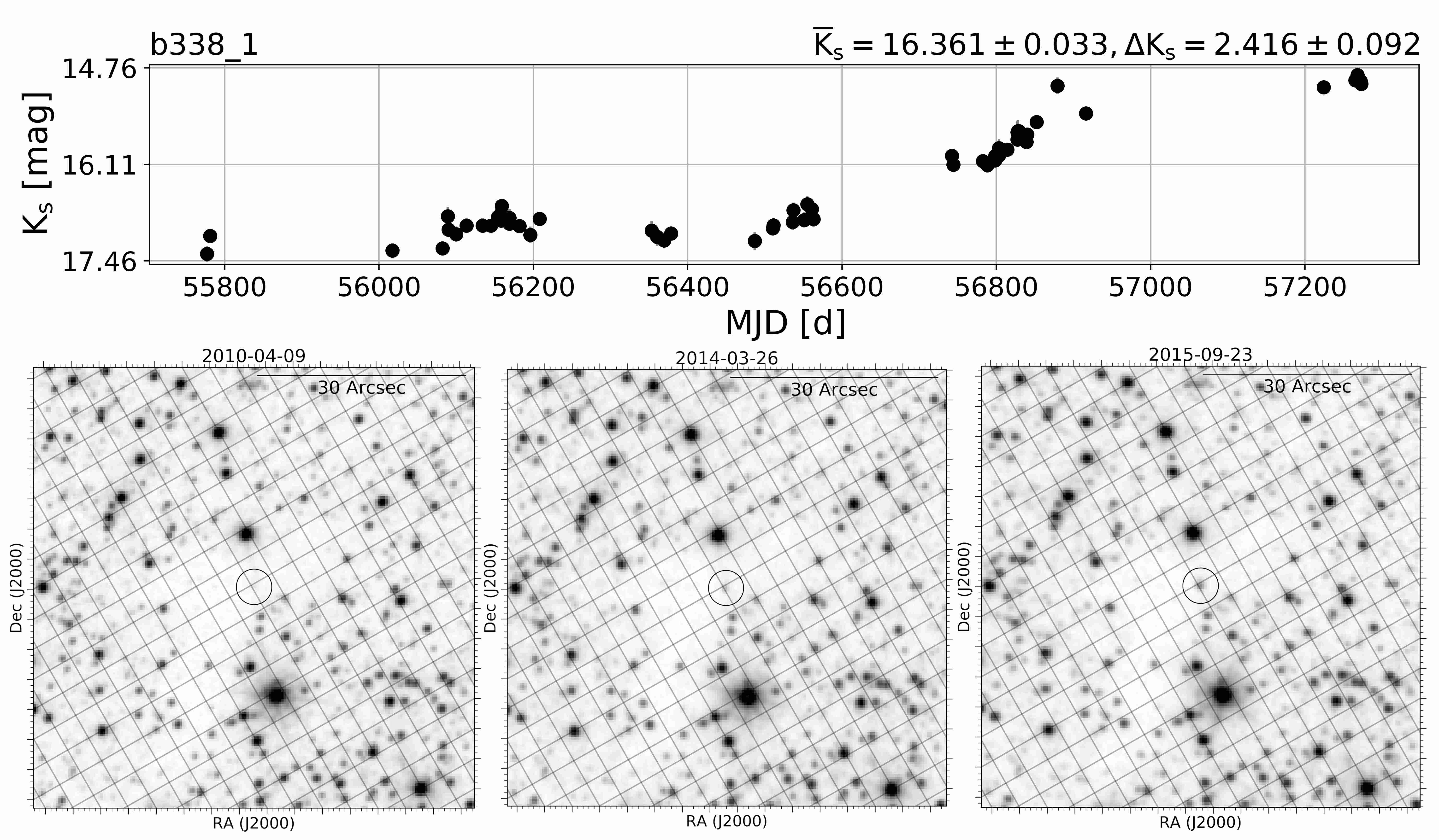
Veamos un caso de la vida real: la estrella periodica 2MASS J17222333-3644037 ha sido reportada como una Cepheida de tipo II. Yo la he encontrado de forma independiente, y la he llamado SFR3_pv12 (prefiero eso a que 2MASS J17222333-3644037).
SFR3_pv12 es una estrella Cefeida de tipo II, una de esas estrellas que nos ayuda a determinar distancias cósmicas. El telescopio VISTA ha hecho 75 mediciones de la luz de este objeto astronómico a lo largo de aproximadamente 5 años (1752 días), y con esta información se ha generado la siguiente serie de tiempo $\{x_n\}$, de la magnitud infrarroja de SFR3_pv12 versus el tiempo:
lc=np.genfromtxt("SFR3_pv12.lc")mjd,mag,err=lc[:,0],lc[:,1],lc[:,2]#Normalizamos el tiempomjd0=min(mjd)-1MJD=mjd-mjd0##MJD = MJD[1:]#mag = mag[1:]#err = err[1:]plt.figure(figsize=(6,2.5))plt.errorbar(MJD,mag,err,0,'ro',ecolor='gray',alpha=0.8,ms=ms-1)plt.xlabel('MJD-%0.1f [d]'%mjd0,fontsize=fz)
plt.ylabel("$K_{s}$ [mag]",fontsize=fz)plt.title("Serie de tiempo de la estrella SFR3_pv12",fontsize=fz)ran=np.linspace(np.min(mag)-np.mean(err),np.max(mag)+np.mean(err),4)rango=np.array([round(ran[i],2)foriinrange(len(ran))])plt.yticks(rango,fontsize=fz)plt.xticks(fontsize=12)plt.gca().invert_yaxis()plt.show()
He ahí la serie de tiempo de una estrella Cefeida tipo II. No parece nada, solo ruido. Aquí no es evidente que exista siquiera un periodo detrás de esta señal. Puede que esto se deba a varios factores: Puede ser el rango temporal en el que están mapeados los ciclos, puede que no exista suficiente cadencia, entre otros.
Estimado público, bienvenido a los datos del mundo real! No pasa nada, solo tenemos que hacer algunas operaciones más y esto tendrá algo de sentido. Usando métodos de análisis armónicos, hemos estimado que el periodo de esta estrella es de $P=14.55$ días, es decir, que cada 14.55 días esta estrella cumple un ciclo.
Entonces, cuando usamos la transformación al espacio de fase $\phi$ que comentamos anteriormente:
p=14.55phase=np.array([(MJD[i]/p-int(MJD[i]/p))foriinrange(len(MJD))])sort=np.array([(mag[j],phase[j],err[j])forjinrange(len(mag))])sort=sort[np.argsort(sort[:,1])]phase=sort[:,1]mag_sort=sort[:,0]err_sort=sort[:,2]plt.figure(figsize=(4,3))plt.title("Curva de luz de SFR3_pv12, con P=14.55 [d]",fontsize=fz)plt.errorbar(phase,mag_sort,err_sort,0,'ro',ecolor='gray',alpha=0.8,ms=ms)plt.xticks([0,0.5,1],fontsize=fz)plt.xlabel('$\phi$',fontsize=fz)plt.ylabel("$K_{s}$ [mag]",fontsize=fz)holi=np.linspace(np.min(mag)-np.mean(err),np.max(mag)+np.mean(err),4)rango=np.array([round(holi[i],2)foriinrange(len(holi))])plt.yticks(rango,fontsize=fz)plt.gca().invert_yaxis()plt.show()
¡Voila! Efectivamente la estrella tiene un periodo definido, dado el orden o la coherencia en su espacio de fase. Esta propiedad es muy importante, ya que existen una serie de métodos que utilizan esta coherencia para determinar el periodo de series de tiempo astronómicas, con el fin de poder identificar el mayor número posible de estrellas que compartan cierto tipo de propiedades (digamos, Cefeidas de tipo II) y con eso, poder estructurar un argumento científico que esgrimir.
Sólo una cosa queda dando vueltas: ¿Cómo se obtiene el periodo, entonces? Esta es la real pregunta. Uno de los métodos más famosos y utilizados es el Periodograma.
El análisis espectral
El análisis espectral es una técnica utilizada para descomponer una señal en sus componentes de frecuencia. Permite estudiar cómo la energía de una señal se distribuye a lo largo del espectro de frecuencias. Dentro de las herramientas de este tipo de análisis está el Periodograma, muy efectivo para caracterizar frecuencias dominantes en series de tiempo mal muestreadas.
Si existe una frecuencia angular $\omega$ dentro de $\{x_n\}$, el periodograma debería ser capaz de encontrala, maximizando el poder espectral $P(\omega)$. Para esto, debemos elegir una grilla de frecuencias y podemos calcular el poder $P(\omega)$ usando la siguiente definición (de entre una multitud de definiciones):
donde $m_i$ son las magnitudes y $t_i$ son los tiempos dentro de la serie de tiempo $\{x_n\}$. El Periodograma debe ser máximo cuando identifica una frecuencia representativa.
muestreo=500#cadencia#Rango en la búsqueda de periodosP_i=10.# Periodo inicialP_f=16.# Periodo final# Calcular el periodograma inicialfrequencies=np.linspace(1/P_f,1/P_i,muestreo)# Frecuencias (1/Periodo)powers=np.zeros_like(frequencies)# Potencia asociada a cada frecuencia# Calculamos la ecuación de arriba:forj,freqinenumerate(frequencies):omega=2*np.pi*freqpowers[j]=np.sum((mag-np.mean(mag))*np.cos(omega*MJD))**2+np.sum((mag-np.mean(mag))*np.sin(omega*MJD))**2# Encontrar el índice de la potencia máximamax_index=np.argmax(powers)freq_max=frequencies[max_index]# Frecuencia que maximiza powers# Calcular el periodo correspondienteperiodo=1/freq_maxperiodos=1/frequenciesprint("El periodo que maximiza el periodograma es %0.2f días:"%periodo)
plt.figure(figsize=(5,3))plt.plot(periodos,powers,'b-')# Línea del periodogramaplt.plot(periodo,np.max(powers),'r*',ms=ms+8)plt.xlabel('Periodo [dias]',fontsize=fz)plt.ylabel('Poder espectral $P(\omega)$',fontsize=fz-2)plt.show()
El periodo que maximiza el periodograma es 14.55 días:
Existe muchas implementaciones de diferentes periodogramas, uno de los más populares es el Periodograma Generalizado de Lomb-Scargle que sin duda realiza un buen trabajo para series de tiempo "suficientemente" muestreadas.
Finalmente, haré una animación para ver cómo las frecuencias que maximizan el periodograma es, a su vez, el que da coherencia al espacio de fase.
Un pseudo algoritmo para implementar la búsqued de periodos en una fuente astronomíca se describe a continuación:
Identificar y obtener la serie de tiempo $\{x_n\}$ de la fuente sospechosa de periodicidad.
Crear una grilla de posibles frecuencias (o periodos) donde uno sospecha que podría encontrarse el periodo.
Aplicar el periodograma, calculando el poder espectral $P(\omega)$.
Identidicar el periodo que maximiza $P(\omega)$
Convertir al espacio de fase y discutir caso a caso.
Como conclusión, destaco la importancia de los procesos cíclicos en la naturaleza, una suposición poderosa para predecir el comportamiento de pequeños trozos del cosmos.
muestreo=350# Número de cuadros en la animaciónP_i=13.0# Periodo inicialP_f=15.0# Periodo finalperiod_step=(P_f-P_i)/muestreo# Cambio del periodo en cada iteración# Calcular el periodograma inicialfrequencies=np.linspace(1/P_f,1/P_i,muestreo)# Frecuencias (1/Periodo)powers=np.zeros_like(frequencies)# Potencia asociada a cada frecuencia# Configuración del gráficofig,(ax1,ax2)=plt.subplots(2,1,figsize=(3.5,4.5),dpi=100,gridspec_kw={'height_ratios':[1,2]})# Configuración del gráfico de periodogramaax1.set_xlabel('periodo [días]',fontsize=fz-3)ax1.set_ylabel('Poder espectral $P(\omega)$',fontsize=fz-2)ax1.xaxis.set_label_position('top')# Mover la etiqueta del eje X arribaax1.xaxis.tick_top()# Mover los ticks del eje X arribaax1.tick_params(axis='y',which='both',left=False,right=False,labelleft=False)# Configuración del gráfico de fase vs magnitudax2.set_xlabel('$\phi$',fontsize=fz)ax2.set_ylabel("$K_{s}$ [mag]",fontsize=fz)ax2.invert_yaxis()ax2.set_xticklabels([])# Dibujar el periodograma inicialforj,freqinenumerate(frequencies):omega=2*np.pi*freqpowers[j]=np.sum((mag-np.mean(mag))*np.cos(omega*MJD))**2+np.sum((mag-np.mean(mag))*np.sin(omega*MJD))**2periodos=1/frequencies# Línea del periodogramaline1,=ax1.plot(periodos,powers,'b-')# Mantener los ejes fijosax1.set_xlim([min(periodos),max(periodos)])# Línea vertical inicial vline=ax1.axvline(x=min(periodos),color='w',linestyle='--',alpha=0.5)# Configurar los ticks del eje Xticks_x=np.linspace(periodos.min(),periodos.max(),6)# 4 valores distribuidos uniformementeax1.set_xticks(ticks_x)ax1.set_xticklabels([f'{tick:.1f}'fortickinticks_x],fontsize=fz-2)# Función de actualización para la animacióndefanimate(i):# Actualizar el periodo y la frecuenciap=P_i+i*period_stepfreq=1/p# Convertir periodo en frecuencia# Actualizar la línea vertical en el periodograma# Esto lo aprendí haciendo esto y me parece increible!!vline.set_xdata(p)# Calcular la fasephase=np.array([(MJD[i]/p-int(MJD[i]/p))foriinrange(len(MJD))])sort=np.array([(phase[j],mag[j],err[j])forjinrange(len(mag))])sort=sort[np.argsort(sort[:,0])]phase=sort[:,0]mag_sort=sort[:,1]err_sort=sort[:,2]# Actualizar los datos de la gráfica de fase vs magnitudax2.clear()# Limpia solo los datos anteriores, no los ejesax2.set_xlabel('$\phi$',fontsize=fz+6)ax2.set_ylabel("$K_{s}$ [mag]",fontsize=fz)# Ocultar los ticks y las líneas en los ejesax2.tick_params(axis='x',which='both',bottom=False,top=False,labelbottom=False)ax2.tick_params(axis='y',which='both',left=False,right=False,labelleft=False)ax2.invert_yaxis()ax2.errorbar(phase,mag_sort,err_sort,0,'ro',ecolor='gray',alpha=0.8,ms=ms)ax2.set_title(f"Periodo = {p:.2f} días",fontsize=fz+1)# Mantener los ejes fijosax2.set_xlim([0,1])# Configuración de la animaciónani=animation.FuncAnimation(fig,animate,frames=muestreo,interval=200,blit=False)# Guardar la animación como un archivo de videoani.save('SFR3_pv12.mp4',writer='ffmpeg',fps=40,dpi=300)plt.show()
El video del resultado puede ser visto en el siguiente video de Youtube:
fromIPython.displayimportHTML# Reemplaza '1eSr9jzxmaM' con el ID real del YouTube Shortvideo_id='1eSr9jzxmaM'# Crear la URL del iframehtml_string=f'''<iframe width="560" height="315" src="https://www.youtube.com/embed/{video_id}" frameborder="0" allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>'''# Mostrar el video en el notebookHTML(html_string)
Hace algunos meses me enteré de la existencia del Núcleo Milenio de Materia Activa, el cual se especializa en el estudio de la dinámica de un gran número de miembros o "agentes", los cuales son unidades independientes que interaccionan con otros agentes vecinos a través de reglas simples y empíricas, por lo menos en sus fundamentos. De esta forma es posible describir el movimiento espontáneo y coherente de ciertos sistemas biológicos, como las bandadas de los pájaros. En el año 1995, el Biólogo físico Tamás Vicsek publicó un estudio llamado NOVEL TYPE OF PHASE TRANSITION IN A SYSTEM OF SELF-DRIVEN PARTICLES donde describe un modelo para describir el movimiento coherente de los cardúmenes y de las bandadas de pájaros en el vuelo.
La materia activa está compuesta de un gran número de «agentes activos», cada uno de los cuales consume energía para moverse o para ejercer fuerzas mecánicas. Debido al consumo de energía, estos sistemas están intrínsecamente fuera de equilibrio térmico. Ejemplos de materia activa son los bancos de peces, bandadas de aves, bacterias, partículas autopropulsadas artificiales, y la auto-organización de los bio-polímeros tales como los microtúbulos y la actina, siendo parte ambos del citoesqueleto de las células vivas. La mayoría de los ejemplos de materia activa son de origen biológico; sin embargo, una gran cantidad del trabajo experimental está dedicado a los sistemas sintéticos.
Sin duda es una definición muy interesante, tomada o inspirada desde la mecánica estadística y aplicada elegántemente en los sistemas complejos biológicos fuera de equilibrio.
El modelo de Vicsek pretende cuantificar matemáticamente la interacción de un miembro del grupo, considerando su vecindad dentro de un rango o distancia de interacción. En este caso, para cada pájaro dentro de la bandada tanto como su posición, velocidad y ángulo del camino serán determinadas por la cantidad de vecinos dentro de una distancia particular, y con eso se creará la "materia activa", generando dichas estructuras coherentes o "materia blanda" que se observan en muchas configuraciones a nuestro alrededor.
Dado que el sistema describe la evolución temporal de cada pájaro miembro de la bandada, dada su posición inicial $\vec{r}(t=0)$ o en cualquier momento $\vec{r}(t)$, la posición cambiará en el siguiente instante $t + \Delta t$ siguiendo la ecuación itinerario (considerando la aceleración $\vec{a}=\vec{0}$):
donde la velocidad $\vec{v}(\theta) = v_0 \left( \cos(\theta)\ \hat{i} + \sin(\theta)\ \hat{j}\right)$ es constante para cada individuo, y la dirección dependerá completamente del ángulo $\theta(t)$, la que a su vez es definida por los agentes en la vecindad local, la que en instante siguiente $t + \Delta t$ es definido de la forma:
donde $\langle \theta \rangle$ representa el valor promedio de todas las direcciones del movimiento de cada vecino dentro del radio de acción ${|r_{i}-r_{j}|<R}$. En la siguiente imagen se grafica la configuración y la cuantificación matemática del modelo de materia activa. El agente azul se está moviendo hacia la izquierda, y su dirección se modificará teniendo en cuenta los agentes dentro de la circunferencia al rededor del agente azul.
Imagen 1: Planteamento del modelo matemático del Vicsek. El agente central azul es influenciado por cada uno de los agentes cercanos (agentes verdes), y su cercanía es cuantificada por la circunferencia de radio $R$. Imagen tomada desde un frame de un video de youtube (ver referencias).
El ángulo de cada ave dentro del círculo es considerado y el valor promedio del ángulo es obtenido de la forma:
Además, el término $\eta\ (t)$ agrega una perturbación aleatoria en la dirección de movimiento, para así incluir algo de realismo al modelo. Todo lo anterior debe ser calculado para cada uno de los pájaros dentro de la bandada, por lo que la complejidad de este modelo recae en el poder de cómputo disponible para calcular cada uno de los anteriores parámetros a través de todos los momentos (o épocas) necesarios para ver la evolución temporal de la bandada.
Todo el procedimiento anterior es explicado a continuación en forma de pseudo-algoritmo de la ejecución del modelo de Vicsek:
Para cada uno de los pájaros dentro de la bandada:
Definir de forma aleatoria las posiciones $\vec{r}_i=(x,y)$ y el angulo inicial $\theta_i$.
Contamos cuántos vecinos están alrededor, dentro del radio $R$, y sus ángulos son considerados.
Calculamos el valor promedio de los ángulos $\langle \theta \rangle$.
Actualizamos la dirección de la la velocidad $\vec{v}$ utilizando el nuevo ángulo $\langle \theta \rangle$.
Agregamos el término de perturbación random $\eta$.
Finalmente, actualizamos la posición de cada pájaro usando la ecuación itinerario en el instante $t + \Delta t$.
Repetir por cada época deseada.
Todo lo anterior es implementado en el siguiente script de python, usando como base la implementación de Philip Mocz (ver referencias). Para la siguiente simulación, se considerará una bandada de 3000 pájaros, en 200 épocas que se diferencian entre ellas por un tiempo $\Delta t=0.01$ segundos. No se diga más.
importnumpyasnpimportmatplotlib.pyplotaspltfrommatplotlibimportanimationimportsysplt.style.use('dark_background')#Parámetros básico del modelo de Vicsek#velocidad inicial:v0=2.0#Número de pájaros:N=3000#Parámetro de ruido angular:eta=0.9#Tamaño de la caja:Lx=4Ly=5#Radio de interacción:R=0.1#paso temporal Delta t:dt=0.01Dt=dt#Número de épocas:Nt=200np.random.seed(N)#Se eligen las posiciones y velocidades de forma random:x=np.random.rand(N)*Lxy=np.random.rand(N)*Lyv_init=np.random.rand(N)*v0theta=2*np.pi*np.random.rand(N)#Calculamos las componentes individualesvx=v_init*np.cos(theta)vy=v_init*np.sin(theta)#Iniciamos el plot y método quiver para visualizar:fig,ax=plt.subplots(figsize=(4,5),dpi=100)quiver=ax.quiver(x,y,vx,vy,color='yellow',linewidth=3.9,headwidth=10,headlength=10)#Función para crear el video:defdibujar_plot(frame,quiver):#Iniciamos los valores para modificiarlos:globalx,y,Lx,Ly,theta,vx,vy,Dt#Limpiamos el gráfico:ax.clear()ax.set_title('Simulación del modelo Vicsek')ax.set_xlim(0,Lx)ax.set_ylim(0,Ly)#Actualizamos la posicion de cada integrantex+=vx*dty+=vy*dt#Condiciones de borde periódicas:#(esto me voló la cabeza)#https://pythoninchemistry.org/sim_and_scat/important_considerations/pbc.htmlx=x%Lxy=y%Ly#Contamos cuántos agentes están dentro del radio R:mean_theta=theta[:]forbinrange(N):neighbors=np.sqrt((x-x[b])**2+(y-y[b])**2)<Rsx=np.mean(np.cos(theta[neighbors]))sy=np.mean(np.sin(theta[neighbors]))mean_theta[b]=np.arctan2(sy,sx)#Añadimos el ruido, hay que restar 0.5 porque los valores random van entre 0 y 1:theta=mean_theta+eta*(np.random.rand(N)-0.5)#Actualizamos la velocidad:vx=v_init*np.cos(theta)vy=v_init*np.sin(theta)#Llevamos la cuenta del tiempo:Dt+=dt#Actualizamos el plot con la nueva época:quiver=ax.quiver(x,y,vx,vy,color='yellow',linewidth=3.9,headwidth=10,headlength=10)ax.set_aspect('equal')ax.tick_params(axis="x",labelsize=0)ax.get_yaxis().set_visible(False)ax.set_xlabel('tiempo t=%.1f [s]'%Dt)
#Guardamos la simulación:ani=animation.FuncAnimation(fig,dibujar_plot,fargs=(quiver,),frames=Nt,interval=100)ani.save('simulation_vicsek.mp4',writer='ffmpeg',fps=100)plt.close()
Un video extendido de esta simulación puede ser encontrado en mi en mi canal de youtube o en mi cuenta de instagram @nicomediap
fromIPython.displayimportHTML# Reemplaza 'AQeqIJLC8lM' con el ID real del YouTube Shortvideo_id='AQeqIJLC8lM'# Crear la URL del iframehtml_string=f'''<iframe width="560" height="315" src="https://www.youtube.com/embed/{video_id}" frameborder="0" allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>'''# Mostrar el video en el notebookHTML(html_string)
He vuelto a la teoría electromagnética, de revisar sus postulados, leyes y aritmética y tengo algunas ideas para ver si es posible mejorar en la visualización y coomprensión de algunos postulados básicos de esta teoría que sin duda alguna ha revolucionado a la humanidad a un nivel aún desconocido.
En un viaje de casi 300 años se pasó de entender las cargas estáticas a los circuitos digitales integrados, y no pocas cosas han ocurrido entre medio. Hitos gigantes han debido ocurrir para que se integraran a las matemáticas conceptos fundamentales como el campo vectorial, su superposición y algunas propiedades fundamentales como el potencial vectorial.
Por supuesto, estas palabras tienen como objetivo el acercamiento de la teoría electromagnética, particularmnete al campo eléctrico y la visualización del campo eléctrico en una región del espacio. Trataré de ser lo más riguroso posible en el tono coloquial con el que tomó vuelo esté escrito.
Además de discutir y experimentar con el uso del campo escalar del potencial electrostático.
Los y las científicas creemos que los campos físicos existen, que el espacio tiene propiedades y pueden ser cuantificados por la medición de ciertas cantidades fundamentales. Por supuesto, ya estamos acostumbrados a la idea de que existen entidades invisibles a nuestro alrededor: el WIFI, la señal del teléfono, etc; o también por su uso en la ciencia ficción con sus "campos de fuerzas" que sirven de escudos.
Pero si logramos bajar la velocidad de la vida, y racionalizamos el hecho de la acción a distancia que caracteriza a algunos campos físicos, resulta increible pensar en esta entidad invisible donde interaccionan la materia que posee carga eléctrica $q$. Pero evidencia de su existencia hay por montones, y no queda más que aceptar la idea.
La teoría electrostática nos dice que el campo eléctrico $\vec{E}(\vec{x})$ en cada punto del espacio 2D $(x,y)$ caracterizado por el vector $\vec{x}=(x,y)$, en el cual actúan una distribución de cargas puntuales $q$ cada una de ellas con posición $\vec{x}^{*}$ es cuantificado por la siguiente ley física:
donde $\epsilon_0$ es la constante conocida como la "permitividad del vacío", estréchamente relacionada con la velocidad de la luz $c$ y la "permeabilidad magnética del vacío" $\mu_0$, y se define de la forma:
donde F expresa las unidades de Faradios, y m los metros de toda la vida. Todo lo anterior puede sonar intimidante, pero esto sólo es la generalidad del comienzo. Básicamente, el campo eléctrico es proporcional del cuadrado de la distancia, entonces en principio bastaría calcular la distancia $d = \sqrt{x^2 + y^2}$ a cada punto y calcular el campo en dicho punto. Por lo tanto, la geometría del problema ha hablado, y podemos considerar coordenadas polares $(r,\theta)$ para así facilitar los cálculos.
Si consideramos el el vector cartesiano $\vec{x} = x \hat{i} + y \hat{j}$, utilizando un cambio de variable tal que:
$$x= r \cos \theta, y= r \sin \theta\, $$
tenemos que el vector cartesiano $\vec{x}$ puede ser descrito por:
\begin{align*}
\vec{x} \>&=\> x \hat{i} + y \hat{j} \\
\>&=\> r \cos \theta\ \hat{i} + r \sin \theta\ \hat{j} \\
\>&=\> r \left( \cos \theta\ \hat{i} + \sin \theta\ \hat{j}\right) \\
\>&=\> r\ \hat{r}(\theta) \\
\end{align*}
Así, podemos simplificar un problema de dos variables $(x,y)$ en solo una $r$, por lo tanto nos enfrentamos a un problema que depende nétamente de la distancia $r$ de cada carga $q$ que interaccione en este campo eléctrico. Como el vector $\vec{x}$ depende sólo de la distancia a las fuentes $\vec{x}^{*}$, el vector que apunta a cada elemento en este espacio será $\left( \vec{x} - \vec{x}^{*} \right)$. Ya con esto podemos usar diréctamente el teoréma de pitágoras para calcular la distancia de la fuente a cada punto del espacio, pero empezaremos por una carga puntual en el origen.
Considerando una carga puntual en el origen (es decir, $(x^{*}, y^{*})=(0,0)$), se puede demostrar que la expresión del campo eléctrico en todo punto es de la forma:
donde cada carga $q$ presentes y considerados en el problema tiene similares propiedades. El vector $\vec{r}=r\ \hat{r}$ es un vector polar el cual debe ser expresado en las coordenadas cartesianas que usaremos para visualizar los efectos. Considerando la distancia desde el origen a cualquier punto del espacio:
Podemos obtener una expresión que será útil para convertir a coordenadas cartesianas. Vean que, de hecho, agregamos un término "$r$" en el tercer paso para manipular la expresión. Entonces, usando el cambio de variable de coordenadas de cartesianas a polares:
La verdad de las cosas no he hemos hecho nada nuevo hasta aquí, yo diría que todo lo anterior se sabe desde hace más de 100 años. Lo realmente interesante es la libertad de la implementación experimental que nos dan los lenguales de programación, que nos permite calcular todo lo anterior de forma iterativa.
Entonces, primero definimos las constantes físicas y luego definimos la función que calculará el campo eléctrico de una carga $q$ en el origen:
#Definimos constantes físicas:#Permeatividad del vacío:epsilon=8.854e-12#Carga fundamental del electrón:q=1.602e-19#Definimos la función que calcula el campo eléctrico desde las coordenadas:defE_origen(q,x,y):"""Retorna el campo de una carga puntual en el origen, de la forma E=(Ex,Ey)."""r=np.sqrt(x**2+y**2)Ex=(q/4*np.pi*epsilon)*x/r**(3/2)Ey=(q/4*np.pi*epsilon)*y/r**(3/2)returnEx,Ey
Lo primero que haremos será iniciar una región para poder calcular la influencia de las fuentes de carga $q$ que están presentes:
importsysimportnumpyasnpimportmatplotlib.pyplotaspltimportseabornassnsfrommatplotlib.patchesimportRectangleplt.style.use('dark_background')#Grilla de puntos que se utilizarán en estos experimentosplt.figure(figsize=(4,5))nx,ny=100,100x=np.linspace(-2,2,nx)y=np.linspace(-4,4,ny)X,Y=np.meshgrid(x,y)plt.scatter(X,Y,s=1.0,color='w',marker='.')plt.xlabel(r'${X}$',fontsize=15)plt.ylabel(r'${Y}$',fontsize=15)plt.show()
Entonces, lo que haremos es cada punto (i,j) de la siguiente matriz, será evaluadaa la función E_origen, luego calculamos el campo eléctrico $\vec{E}(x,y)$ desde la suma independiente de sus componentes individuales $E_{x}$ y $E_{y}$
# Iniciamos los valores de cada componente:Ex=np.zeros((ny,nx))Ey=np.zeros((ny,nx))# Calculamos las componentes del campo eléctrico:Ex,Ey=E_origen(q,x=X,y=Y)fig=plt.figure(figsize=(4,5))#Usamos "streamlines" para visualizar el campo eléctrico:color=np.log(np.hypot(Ex,Ey))plt.streamplot(x,y,Ex,Ey,color=color,linewidth=1.2,cmap=plt.cm.jet,density=1.3,arrowstyle='->',arrowsize=1.5,zorder=0)#Dibujamos la carga y su nombre:plt.scatter(0,0,zorder=1,s=600,edgecolor='k',facecolor='red')plt.text(-0.1,-0.08,'$q$',fontsize=18,c='k')plt.xlabel(r'${X}$',fontsize=15)plt.ylabel(r'${Y}$',fontsize=15)plt.show()
Un hito: la visualización del campo eléctrico más simple que existe!! Desde acá podemos ver que cargas positivas emite líneas de campo eléctrico. También puede decirse que es fuente de campo eléctrico, aunque puede ser algo redundante ya que el hecho de poseer carga ya posee interacción en el campo.
Cargas negativas $-q$ recibe líneas de campo eléctrico, también conocido como un "sumidero", término que es prestado de otros campos de la física. Más adelante está el ejemplo de la interacción de una carga $-q$ que interacciona en el espacio.
Como nos enfrentamos a un problema que depende nétamente de la distancia $r$ de cada carga $q$ que interaccione en este campo eléctrico, el vector que apunta a cada elemento en este espacio, considerando la influencia de las cargas presentes será $\left( \vec{x} - \vec{x}^{*} \right)$.
Por suerte, podemos seguir usando nuestro querido teoréma de pitágoras y calcular la distancia a cada punto del espacio de la forma:
$$r = \sqrt{ (x-x^{*})^2 + (y-y^{*})^2}$$
De la misma forma anterior, considerando la descomposición:
Con esto, podemos localizar una carga $q$ en cualquier lugar de este espacio de dos dimensiones.
defE_puntual(q,posx,posy,x,y):"""Retorna el campo de una carga puntual, de la forma E=(Ex,Ey), informada su posición."""r=np.sqrt((x-posx)**2+(y-posy)**2)Ex=(q/4*np.pi*epsilon)*(x-posx)/r**(3/2)Ey=(q/4*np.pi*epsilon)*(y-posy)/r**(3/2)returnEx,Ey
Usaremos la función antes descrita para colocar una carga $q$ en la posición $(x^*,y^*)=(0,2)$
Ex=np.zeros((ny,nx))Ey=np.zeros((ny,nx))posicion=[0,2]#Calculamos el campo eléctrico de una carga en (0.2)Ex,Ey=E_puntual(q,posx=posicion[0],posy=posicion[1],x=X,y=Y)fig=plt.figure(figsize=(4,5))#Usamos "streamlines" para visualizar el campo eléctrico:color=np.log(np.hypot(Ex,Ey))plt.streamplot(x,y,Ex,Ey,color=color,linewidth=1.2,cmap=plt.cm.jet,density=1.5,arrowstyle='->',arrowsize=1.5,zorder=0)#Dibujamos la carga y su nombre:plt.scatter(posicion[0],posicion[1],zorder=1,s=800,edgecolor='k',facecolors='red')plt.text(-0.1,1.95,'$q$',fontsize=18,c='k')plt.xlabel(r'${X}$',fontsize=15)plt.ylabel(r'${Y}$',fontsize=15)plt.show()
Usaremos la misma función antes descrita para colocar una carga de signo contrario $-q$ en la posición $(x^*,y^*)=(0,-2)$
Ex=np.zeros((ny,nx))Ey=np.zeros((ny,nx))posicion=[0,-2]#Calculamos el campo eléctrico de una carga en (0.2)Ex,Ey=E_puntual(-q,posx=posicion[0],posy=posicion[1],x=X,y=Y)fig=plt.figure(figsize=(4,5))#Usamos "streamlines" para visualizar el campo eléctrico:color=np.log(np.hypot(Ex,Ey))plt.streamplot(x,y,Ex,Ey,color=color,linewidth=1.2,cmap=plt.cm.jet,density=1.5,arrowstyle='->',arrowsize=1.5,zorder=0)#Dibujamos la carga y su nombre:plt.scatter(posicion[0],posicion[1],zorder=1,s=800,edgecolor='k',facecolors='blue')plt.text(-0.25,-2.07,'$-q$',fontsize=16,c='w')plt.xlabel(r'${X}$',fontsize=15)plt.ylabel(r'${Y}$',fontsize=15)plt.show()
Veamos que esta carga es negativa, por lo que atrae líneas de campo eléctrico. Las cargas positivas emiten líneas de campo eléctrio, las cargas negativas atraen líneas de campo, es por esto que el dicho popular dice: "los opuestos de atraen".
Otra gran propiedad aplicable al campo eléctrico es el principio de superposicion, es decir que es posible calcular el campo eléctrico total $\vec{E}_{total}$ en una región es igual a la suma individual del campo eléctrico provocado por cada fuente. La suma individual de cada componente del sistema dará como resultado el campo total.
En general, podríamos tener $N$ cargas puntuales y el campo eléctrico total en cada punto será las sumas individuales de cada campo eléctrico en ese punto. Dicho de forma matemática:
Usaremos esta propiedad en las dos cargas antes creadas: la carga positiva $q$ creada en los puntos (x,y)=(0,2) y la carga negativa $-q$ que hemos cread en los puntos (x,y)=(0,-2). Así, podemos expresar la superposición de la forma:
En el caso de dos cargas opuestas, alineadas en el eje x, se forma el patrón de un dipolo eléctrico:
Ex=np.zeros((ny,nx))Ey=np.zeros((ny,nx))#Ponemos una carga en las coordenadas (x,y)=(0,2) y calculamos su campo:ex_q1,ey_q1=E_puntual(q,posx=0,posy=2,x=X,y=Y)#Ponemos otra carga en las coordenadas (x,y)=(0,-2) y calculamos su campo:ex_q2,ey_q2=E_puntual(-q,posx=0,posy=-2,x=X,y=Y)#Sumamos la contribución al campo general, usando la propiedad de superposición:Ex=ex_q1+ex_q2Ey=ey_q1+ey_q2fig=plt.figure(figsize=(4,5))color=np.log(np.hypot(Ex,Ey))plt.streamplot(x,y,Ex,Ey,color=color,linewidth=1.2,cmap=plt.cm.jet,density=1.,arrowstyle='->',arrowsize=1.5,zorder=0)#Dibujamos las cargasplt.scatter(0,2,zorder=1,s=600,facecolors='red',edgecolor='k',label='$q$')plt.text(-0.08,1.95,'$q$',fontsize=16,c='k')plt.scatter(0,-2,zorder=1,s=600,facecolors='blue',edgecolor='k',label='$-q$')plt.text(-0.2045,-2.07,'$-q$',fontsize=14,c='w')plt.xlabel(r'${X}$',fontsize=15)plt.ylabel(r'${Y}$',fontsize=15)plt.title('Dipolo eléctrico',fontsize=14)plt.show()
Ya, todo esto fue lo básico: lo mínimo que debes saber para poder meter las manos en un mundo donde el que prueba es el que avanza. De aquí en adelante dependerá de tu ingenio y cómo puedes construir estructuras usando esta lógica.
Una de las formas efectivas que existen es demostrada en este link del libro Learning Scientific Programming with Python, es el de "crear" un grupo de cargas en posiciones espefícicas, y luego se itera sobre ellas para agregar sus contribuciones individuales de campo eléctrico sobre la región de interés. Dicho de forma estructurada:
Definir un contenedor $\mathtt{cargas}$ donde se agregarán cargas puntuales.
Definir cómo se distribuirán las cargas, y su signo (q o -q).
Agregar la carga al contenedor $\mathtt{cargas}$.
Hacer un loop sobre cada carga, y que su contribución se haga individualmente.
Visualización del campo $\vec{E}(x,y)$
Construiré estructuras sencillas, seguidas en la lógica de las funciones que hemos creado. Por ejemplo podemos crear una "barra" cargada positivamente, hecha por una fila de cargas puntuales positivas y evaluaremos cada campo eléctrico por separado. Para esto, usaremos 100 cargas individuales, equiespaciadas entre -5 a 5 en el eje $y$. También, vamos a considerar que las estructuras de color roja están cargadas positivamente (fuentes de campo eléctrico), y las estructuras azules serán cargas negativas (receptoras de campo eléctrico).
#Definimos el número de cargas a usarnq=100#Creamos un contenedor vacío de cargas a evaluarcargas=[]#Línea recta a lo larga del eje Y:coords_y=np.linspace(-5,5,nq)#Iteramos sobre las coordenadas en el eje yforcoordenadaincoords_y:#Agregamos una carga q, con coordenada x=0, y coordenada y=coordenadacargas.append((q,0,coordenada))
#Grilla de puntos que se utilizarán en estos experimentosplt.figure(figsize=(4,5))x=np.linspace(-4,4,nx)y=np.linspace(-8,8,ny)X,Y=np.meshgrid(x,y)Ex=np.zeros((ny,nx))Ey=np.zeros((ny,nx))#Hacemos el loop final donde el campo de cada carga individual #se usa para calcular el campo final:#Por cada carga dentro de la lista de cargas:forcargaincargas:ex,ey=E_puntual(*carga,x=X,y=Y)#En cada iteración, se le agrega ex a Ex.Ex+=exEy+=eycolor=np.log(np.hypot(Ex,Ey))plt.streamplot(x,y,Ex,Ey,color=color,linewidth=1.3,cmap=plt.cm.hot,density=1.3,arrowstyle='->',arrowsize=1.5,zorder=0)#pintamos los objetos plt.gca().add_patch(Rectangle((-0.15,-5),0.3,10,edgecolor='black',facecolor='red',fill=True,lw=2))plt.xlabel(r'${X}$',fontsize=15)plt.ylabel(r'${Y}$',fontsize=15)plt.title(r'${\vec{E}(x,y)}$',fontsize=14,color='yellow')plt.show()
Una barra super saiyajin jajaja. Ahora, agregaremos dos barras pero de cargas diferentes, buscando la configuración de "placas paralelas". Para esto limpiaremos el contenedor $\mathtt{cargas}$ y agregaremos dos estructuras similares, separadas en el eje x. No se diga más!
#Definimos el número de cargas a usarnq=200#Creamos un contenedor vacío de cargas a evaluarcargas=[]#Línea recta a lo larga del eje Y:coords_izq_y=np.linspace(-5,5,nq)forcoordenadaincoords_izq_y:cargas.append((-q,-1,coordenada))#Línea recta a lo larga del eje Y:coords_der_y=np.linspace(-5,5,nq)forcoordenadaincoords_der_y:cargas.append((q,1,coordenada))Ex=np.zeros((ny,nx))Ey=np.zeros((ny,nx))#Hacemos el loop final donde el campo de cada carga individual se usa #para calcular el campo final. Por cada carga dentro de la lista de cargas:forcargaincargas:ex,ey=E_puntual(*carga,x=X,y=Y)Ex+=exEy+=eyfig=plt.figure(figsize=(4,5))color=np.log(np.hypot(Ex,Ey))plt.streamplot(x,y,Ex,Ey,color=color,linewidth=1.4,cmap=plt.cm.hot,density=1.,arrowstyle='->',arrowsize=1.1,zorder=0)#pintamos los objetos plt.gca().add_patch(Rectangle((-1.2,-5),0.3,10,edgecolor='black',facecolor='blue',fill=True,lw=2))plt.gca().add_patch(Rectangle((1,-5),0.3,10,edgecolor='black',facecolor='red',fill=True,lw=2))plt.xlabel(r'${X}$',fontsize=15)plt.ylabel(r'${Y}$',fontsize=15)plt.title(r'${\vec{E}(x,y)}$',fontsize=14,color='yellow')plt.show()
Interesante, se ve el efecto de las placas paralelas en la uniformidad del campo eléctrico entre ellas!. Genial. Esta aproximación de cargas puntuales puestas espacialmente una al lado de la otra funciona bien.
Hagamos un zoom al uno de los bordes de las placas paralelas:
#Grilla de puntos que se utilizarán en estos experimentosx=np.linspace(-2,2,nx)y=np.linspace(-4,4,ny)X,Y=np.meshgrid(x,y)#Definimos el número de cargas a usarnq=150#Creamos un contenedor vacío de cargas a evaluarcargas=[]#Línea recta a lo larga del eje Y:coords_izq_y=np.linspace(-0.5,8,nq)forcoordenadaincoords_izq_y:cargas.append((-q,-1,coordenada))#Línea recta a lo larga del eje Y:coords_der_y=np.linspace(-0.5,8,nq)forcoordenadaincoords_der_y:cargas.append((q,1,coordenada))plt.figure(figsize=(4,5))Ex=np.zeros((ny,nx))Ey=np.zeros((ny,nx))#Hacemos el loop final donde el campo de cada carga individual se usa para calcular el campo final:#Por cada carga dentro de la lista de cargas:forcargaincargas:ex,ey=E_puntual(*carga,x=X,y=Y)Ex+=exEy+=ey# Plot the streamlines with an appropriate colormap and arrow stylecolor=np.log(np.hypot(Ex,Ey))plt.streamplot(x,y,Ex,Ey,color=color,linewidth=2,cmap=plt.cm.hot,density=1.3,arrowstyle='->',arrowsize=1.5,zorder=0)#pintamos los objetos plt.gca().add_patch(Rectangle((-1.13,-0.5),0.3,10,edgecolor='black',facecolor='blue',fill=True,lw=2))plt.gca().add_patch(Rectangle((0.88,-0.5),0.3,10,edgecolor='black',facecolor='red',fill=True,lw=2))plt.xlabel(r'${X}$',fontsize=15)plt.ylabel(r'${Y}$',fontsize=15)plt.xlim(-2,2)plt.ylim(-2,3)plt.title(r'${\vec{E}(x,y)}$',fontsize=14,color='yellow')plt.show()
Como dije, de aquí en adelante la verdad sólo depende de cómo se agregenen las coordenadas de las cargas y sus magnitudes. Una de las cosas que se me ocurrió construir fue una elipse, que cada una de sus mitades tiene diferente signo. Lo que si, tuve que improvisar en el dibujo de las cargas en el plot, porque no sé aún cómo representar superficies arbitrarias con los bordes delineados. Con las barras fue fácil, pero ahora ya no hay tiempo.
#Definimos el número de cargas a usarnq=200#Creamos un contenedor vacío de cargas a evaluarcargas=[]escala1,escala2=1,2#Semi circulo derecho#puntos entre angulos -pi/2 y + pi/2coords_y=np.linspace(-np.pi/2,np.pi/2,nq)forcoordenadaincoords_y:cargas.append((q,escala1*np.cos(coordenada),escala2*np.sin(coordenada)))#Semi circulo izquierdo #puntos entre angulos pi/2 y + 3pi/2coords_y=np.linspace(np.pi/2,3*np.pi/2,nq)forcoordenadaincoords_y:cargas.append((-q,escala1*np.cos(coordenada),escala2*np.sin(coordenada)))
x=np.linspace(-4,4,nx)y=np.linspace(-8,8,ny)X,Y=np.meshgrid(x,y)Ex=np.zeros((ny,nx))Ey=np.zeros((ny,nx))#Hacemos el loop final donde el campo de cada carga individual se usa para calcular el campo final:#Por cada carga dentro de la lista de cargas:forcargaincargas:ex,ey=E_puntual(*carga,x=X,y=Y)Ex+=exEy+=eyfig=plt.figure(figsize=(4,5))# Plot the streamlines with an appropriate colormap and arrow stylecolor=np.log(np.hypot(Ex,Ey))plt.streamplot(x,y,Ex,Ey,color=color,linewidth=1.3,cmap=plt.cm.hot,density=1.3,arrowstyle='->',arrowsize=1.5,zorder=0)#pintamos los objetos forq,posx,posyincargas:ifq<0:plt.scatter(posx,posy,zorder=1,s=90,facecolors='blue')else:plt.scatter(posx,posy,zorder=1,s=90,facecolors='red')plt.xlabel(r'${X}$',fontsize=15)plt.ylabel(r'${Y}$',fontsize=15)plt.title(r'${\vec{E}(x,y)}$',fontsize=14,color='orange')plt.show()
Y si seguimos intruseando en los parámetros de estas estructuras, podemos crear visualizaciones cada vez más interesantes y estéticas, como la siguiente que logré al rotar el eje de simetría de la epilse polarizada:
x=np.linspace(-4,4,nx)y=np.linspace(-8,8,ny)X,Y=np.meshgrid(x,y)#Definimos el número de cargas a usarnq=200#Creamos un contenedor vacío de cargas a evaluarcargas=[]escala1,escala2=3,7angulo=80#Semi circulo derecho#puntos entre angulos -pi/2 y + pi/2coords_y=np.linspace(-np.pi/2,np.pi/2,nq)forcoordenadaincoords_y:cargas.append((q,escala1*np.cos(coordenada+angulo),escala2*np.sin(coordenada)))#Semi circulo izquierdo #puntos entre angulos pi/2 y + 3pi/2coords_y=np.linspace(np.pi/2,3*np.pi/2,nq)forcoordenadaincoords_y:cargas.append((-q,escala1*np.cos(coordenada+angulo),escala2*np.sin(coordenada)))Ex=np.zeros((ny,nx))Ey=np.zeros((ny,nx))#Hacemos el loop final donde el campo de cada carga individual se usa para calcular el campo final:#Por cada carga dentro de la lista de cargas:forcargaincargas:ex,ey=E_puntual(*carga,x=X,y=Y)Ex+=exEy+=eyfig=plt.figure(figsize=(4,5))# Plot the streamlines with an appropriate colormap and arrow stylecolor=np.log(np.hypot(Ex,Ey))plt.streamplot(x,y,Ex,Ey,color=color,linewidth=1.2,cmap=plt.cm.hot,density=1.3,arrowstyle='->',arrowsize=1.5,zorder=0)#pintamos los objetos forq,posx,posyincargas:ifq<0:plt.scatter(posx,posy,zorder=1,s=90,facecolors='blue')else:plt.scatter(posx,posy,zorder=1,s=90,facecolors='red')plt.xlabel(r'${X}$',fontsize=15)plt.ylabel(r'${Y}$',fontsize=15)plt.title(r'${\vec{E}(x,y)}$',fontsize=14,color='orange')plt.show()
Ya para finalizar, una cantidad aún más fudamental que el campo eléctrico es el potencial electrostático. Para una carga puntual, el potencial está definido por:
Es una cantidad fundamental, ya que es un campo escalar, es decir que para cada punto (x,y) existe un valor $\phi(\vec{x})$ asociado. Por consecuencia, el potencial eléctrico es una distribución en el espacio, y no dos o más valores asociadas, como es el caso del campo eléctrico $\vec{E}$. Por supuesto que el vínculo entre el potencial y el cámpo es estrecha, dado que el Campo eléctrico es el gradiente del potencial eléctrico:
$$\vec{E} = -\vec{\nabla}\phi(\vec{x}),$$
es decir, el campo eléctrico en realidad sigue la dirección donde el potencial $\phi$ cambiará más rapidamente, generando superficies equipotenciales en lugares que sean perpendiculares a las líneas de campo eléctrico.
El potencial es definido en la siguiente función llamada $\mathtt{P\_ puntual}$:
defP_puntual(q,posx,posy,x,y):"""Retorna el potencial eléctrico de una carga puntual"""r=np.sqrt((x-posx)**2+(y-posy)**2)Pot=(1/(4*np.pi*epsilon))*(q/r)returnPot
Usaremos algunas de las configuraciones anteriores y visualizaremos el potencial $\phi(\vec{x}-\vec{x}^{*})$ en conjunto con los campos eléctricos. Hasta usaremos el mismo bucle para calcular el campo escalar:
x=np.linspace(-2,2,nx)y=np.linspace(-4,4,ny)X,Y=np.meshgrid(x,y)Ex=np.zeros((ny,nx))Ey=np.zeros((ny,nx))#Ponemos una carga en las coordenadas (x,y)=(0,-2) y calculamos su campo:ex_q1,ey_q1=E_puntual(-q,posx=0,posy=-2,x=X,y=Y)#Ponemos otra carga en las coordenadas (x,y)=(0,2) y calculamos su campo:ex_q2,ey_q2=E_puntual(q,posx=0,posy=2,x=X,y=Y)#Sumamos la contribución al campo general, usando la propiedad de superposición:Ex=ex_q1+ex_q2Ey=ey_q1+ey_q2fig=plt.figure(figsize=(4,5))# Plot the streamlines with an appropriate colormap and arrow stylecolor=np.log(np.hypot(Ex,Ey))plt.streamplot(x,y,Ex,Ey,color=color,linewidth=0.8,cmap=plt.cm.hot,density=1.,arrowstyle='->',arrowsize=1.5,zorder=0)#Ponemos una carga en las coordenadas (x,y)=(0,-2) y calculamos su campo:P_1=P_puntual(-q,posx=0,posy=-2,x=X,y=Y)#Ponemos otra carga en las coordenadas (x,y)=(0,2) y calculamos su campo:P_2=P_puntual(q,posx=0,posy=2,x=X,y=Y)#Sumamos la contribución al campo general, usando la propiedad de superposición:P_tot=P_1+P_2contornos=np.linspace(np.min(P_tot),np.max(P_tot),45)cset=plt.contour(X,Y,P_tot,contornos,colors='w')#Dibujamos las cargasplt.scatter(0,2,zorder=1,s=800,facecolors='red',edgecolor='k',label='q')plt.scatter(0,-2,zorder=1,s=800,facecolors='blue',edgecolor='k',label='-q')#plt.legend(loc='right',fontsize=20)plt.xlabel(r'${X}$',fontsize=15)plt.ylabel(r'${Y}$',fontsize=15)plt.title(r'${\phi(x,y)}$',fontsize=14)plt.show()
#Grilla de puntos que se utilizarán en estos experimentosplt.figure(figsize=(4,5))nx,ny=100,100x=np.linspace(-2,2,nx)y=np.linspace(-2,12,ny)X,Y=np.meshgrid(x,y)#Definimos el número de cargas a usarnq=150#Creamos un contenedor vacío de cargas a evaluarcargas=[]P_tot=0#Línea recta a lo larga del eje Y:coords_izq_y=np.linspace(-0.5,10,nq)forcoordenadaincoords_izq_y:cargas.append((-q,-1,coordenada))#Línea recta a lo larga del eje Y:coords_der_y=np.linspace(-0.5,10,nq)forcoordenadaincoords_der_y:cargas.append((q,1,coordenada))# Electric field vector, E=(Ex, Ey), as separate componentsEx=np.zeros((ny,nx))Ey=np.zeros((ny,nx))#Hacemos el loop final donde el campo de cada carga individual se usa para calcular el campo final:#Por cada carga dentro de la lista de cargas:forcargaincargas:ex,ey=E_puntual(*carga,x=X,y=Y)Ex+=exEy+=eyP_tot+=P_puntual(*carga,x=X,y=Y)color=np.log(np.hypot(Ex,Ey))plt.streamplot(x,y,Ex,Ey,color=color,linewidth=0.6,cmap=plt.cm.hot,density=1.3,arrowstyle='->',arrowsize=1.5,zorder=0)#pintamos los objetos plt.gca().add_patch(Rectangle((-1.13,-0.5),0.3,10,edgecolor='black',facecolor='blue',fill=True,lw=2))plt.gca().add_patch(Rectangle((0.88,-0.5),0.3,10,edgecolor='black',facecolor='red',fill=True,lw=2))plt.xlabel(r'${X}$',fontsize=15)plt.ylabel(r'${Y}$',fontsize=15)contornos=np.linspace(np.min(P_tot),np.max(P_tot),20)plt.contour(X,Y,P_tot,contornos,colors='w')plt.title(r'${\phi(x,y)}$',fontsize=14)plt.show()
x=np.linspace(-4,4,nx)y=np.linspace(-8,8,ny)X,Y=np.meshgrid(x,y)#Definimos el número de cargas a usarnq=200#Creamos los contenedores vacíos de los campos:cargas=[]P_tot=0escala1,escala2=2,5#Semi circulo derecho#puntos entre angulos -pi/2 y + pi/2coords_y=np.linspace(-np.pi/2,np.pi/2,nq)forcoordenadaincoords_y:cargas.append((q,escala1*np.cos(coordenada),escala2*np.sin(coordenada)))#Semi circulo izquierdo #puntos entre angulos pi/2 y + 3pi/2coords_y=np.linspace(np.pi/2,3*np.pi/2,nq)forcoordenadaincoords_y:cargas.append((-q,escala1*np.cos(coordenada),escala2*np.sin(coordenada)))Ex=np.zeros((ny,nx))Ey=np.zeros((ny,nx))#Hacemos el loop final donde el campo de cada carga individual se usa para calcular el campo final:#Por cada carga dentro de la lista de cargas:forcargaincargas:ex,ey=E_puntual(*carga,x=X,y=Y)Ex+=exEy+=eyP_tot+=P_puntual(*carga,x=X,y=Y)fig=plt.figure(figsize=(4,5))color=np.log(np.hypot(Ex,Ey))plt.streamplot(x,y,Ex,Ey,color=color,linewidth=0.7,cmap=plt.cm.hot,density=1.3,arrowstyle='->',arrowsize=1.5,zorder=0)#pintamos los objetos forq,posx,posyincargas:ifq<0:plt.scatter(posx,posy,zorder=1,s=90,facecolors='blue')else:plt.scatter(posx,posy,zorder=1,s=90,facecolors='red')contornos=np.linspace(np.min(P_tot),np.max(P_tot),20)plt.contour(X,Y,P_tot,contornos,colors='w')plt.xlabel(r'${X}$',fontsize=15)plt.ylabel(r'${Y}$',fontsize=15)plt.title(r'${\phi(x,y)}$',fontsize=14)plt.show()
Finalmente, construiremos una última forma de visualizar el potencial y las líneas de campo eléctrico, dado que las últimas imágenes contienen demasiada información. Como el potencial $\phi(x,y)$ es básicamente una imagen, usamos el método $\mathtt{imshow}
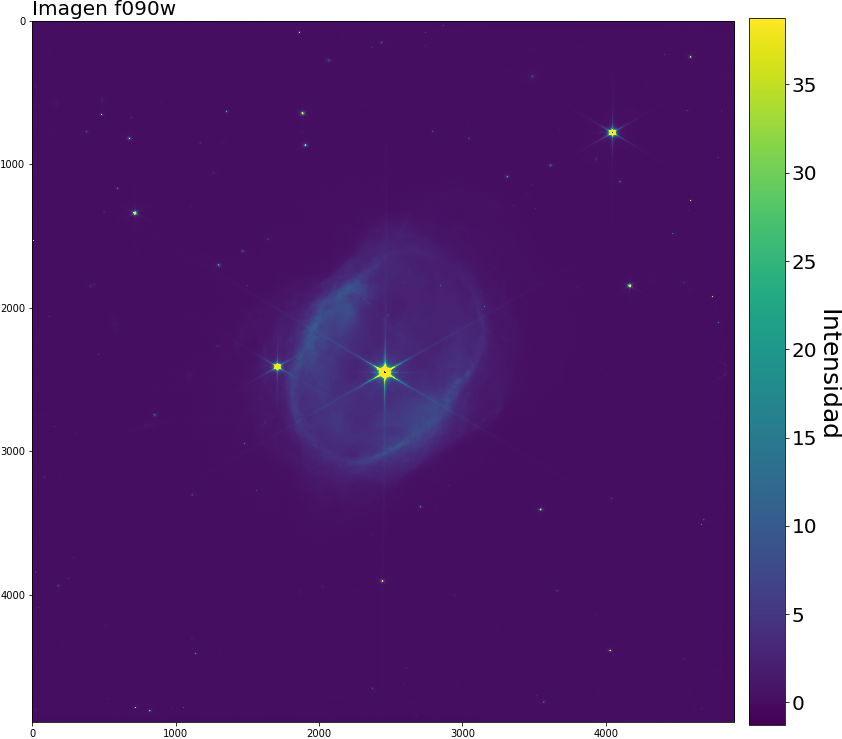
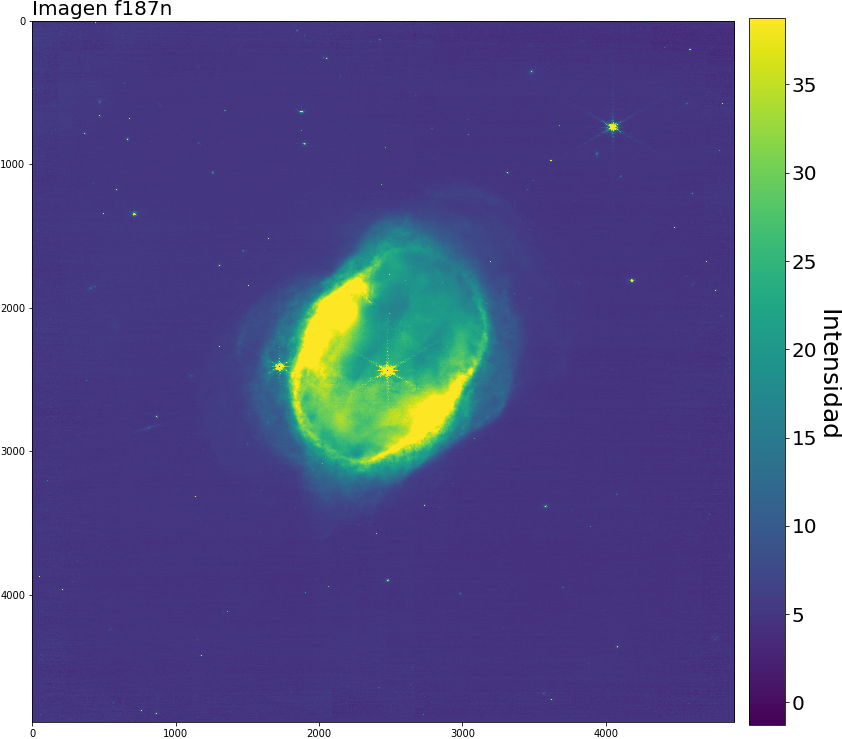
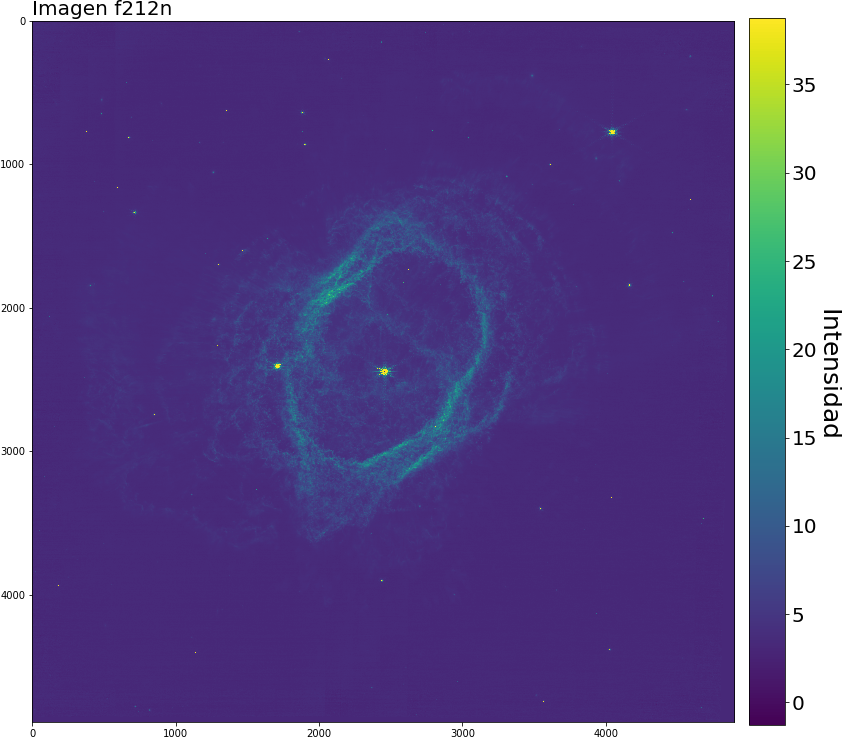
Oculta a plena luz visible se encuentra una solitaria nebulosa oscura llamada LDN1527:, una región interestelar de polvo y gas densa y fría que no permite el paso de la luz visible; son objetivos interesantes de estudiar dado los objetos que se pueden refugiar por detrás del material en algunas longuitudes de onda más pequeñas.
Y ya sabemos que el telescopio espacial James Webb (JWST) anda suelto, así que apuntó su avanzada óptica a las coordenadas Ascension Recta y declinación $(RA,Dec) = (69.9708^{\circ},+25.7500^{\circ})$ del hemisferio norte, su cámara infrarroja NIRCAM consiguió obtener información de la luz infrarroja que emitía por detrás del polvo y vaya sorpresa que nos llevamos.
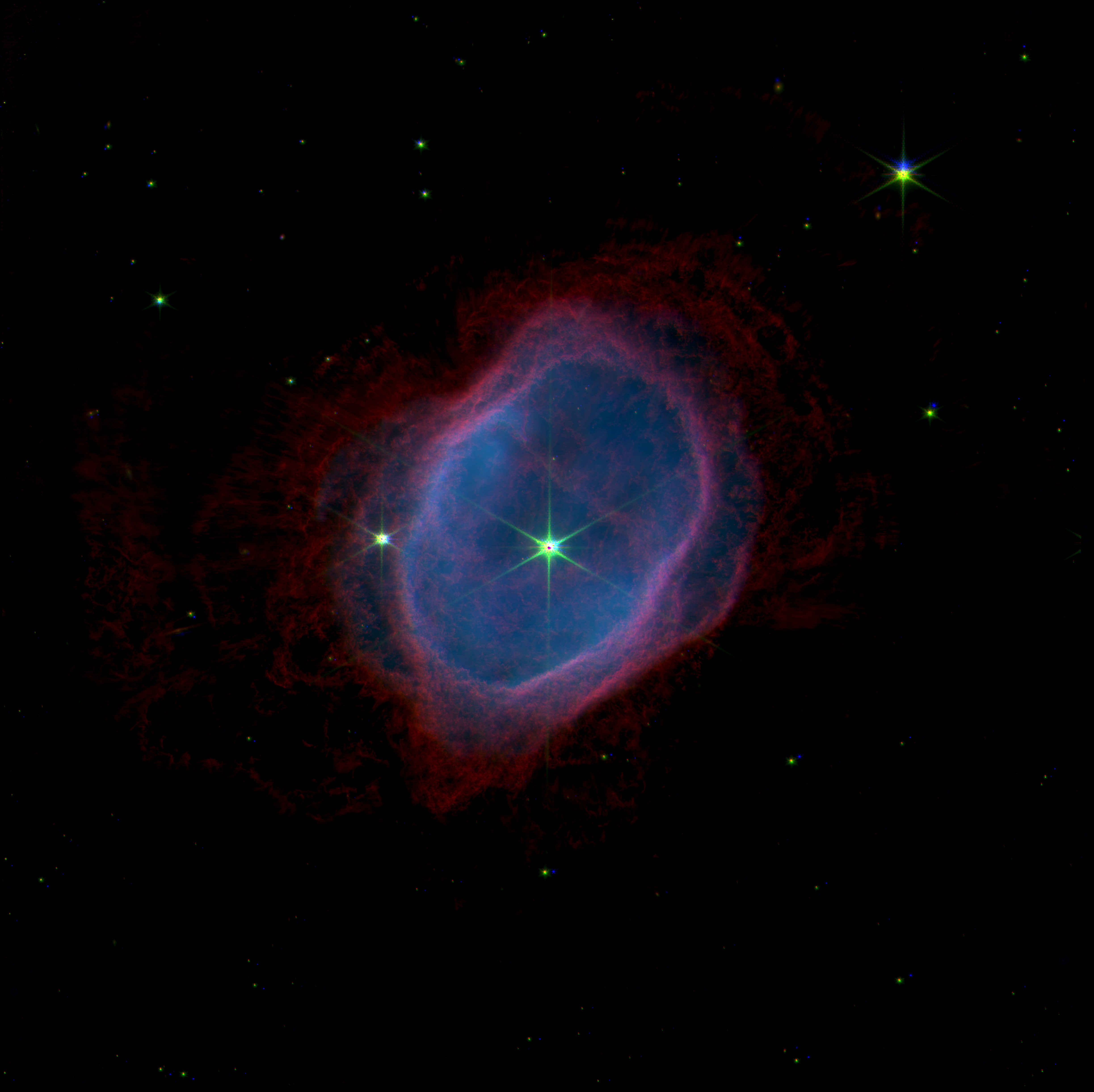
Imagen 1: La vista del JWST de la nebulosa oscura LDN1527. Imagen tomada Galeria del JWST, muestra la escala y las imágenes usadas para la composición.
Una estrella que nace:
En las etapas iniciales de la formación estelar son caóticas: Hay muchos componentes identificables como disco de acreción o el material circundante que se mueven a diferentes velocidades, en constante movimiento y atadas gravitatoriamente al objeto joven del centro. En general las estrellas tampoco nacen aisladas, sino que en ambientes densos y frios, el cual justamente es el caso de LDN1527, por lo tanto, se sospechaba que habría objetos estelares jóvenes (YSOs por sus siglas en inglés) detrás de su material interestelar.
La estructura de LDN1527 es como la de un reloj de arena. En el centro está el objeto estelar jóven, rodeado de un disco de acreción (un disco de polvo y gas que rodea a la protostrella y se encuentra en proceso de caer hacia ella) que obscurece la fuente central en ciertos lugares. Pareciera que el disco se observa “de canto”, o también se dice edge-on, es mas cool.
Como si eso ya no bastara, este YSO posee flujo bipolar, donde el material es expulsado de la protostrella en direcciones contrarias, dada la prescencia de un disco de acreción o un fuerte campo magnético. Hacia arriba y abajo del reloj de arena, se ven filamentos brillantes e iluminados desde el centro, lo que ejecta la materia. La masa expulsada podría llegar a formar nubes de polvo y gas en su camino (Ejemplos de esto son objetos Herbig-Haro (HH) numero 30: HH 30:, el HH 34: o HH 111:. Estos lanzamientos de material enriquecen el ambiente, lo que podría afectar la formación de planetas en el disco protoplanetario alrededor del YSO, interfiriendo en la acumulación de masa.
Hay muy pocas imágenes detalladas de este tipo de objetos. Esta imágen representa muy bien por qué algunas de sus series de tiempo son estocásticas, dada la inmensa cantidad de componentes que forman la medición de su luz.
También, es una linda imagen, y como los datos son publicos, vamos a componer nuestra propia versión :D. Primero, hay que descargar los datos disponibles de LDN1527 tomados con la NIRCAM, que son:
f335m: Filtro de banda “mediana”, sensible a los Hidrocarburos aromáticos policíclicos (o PAH) y al metano CH4.
f444w: Filtro de banda ancha de uso general.
f444w-f470n: Imagen definida entre las restas de las imágenes descritas. Desde la documetanción de los filtros:, el filtro f444w bloquea los filtros estrechos, entre ellos el f470n. En esta longuitud de onda, el filtro f470n es sensible a la presencia de hidrógeno molecular.
Mejor todo en una tabla:
ID
tipo filtro
longuitud de onda
Especialidad
f335m
median
3.35 μm
PAH, CH4
f444w
wide
4.44 μm
General
f470n
narrow
4.7 μm
Hidrogeno molecular
Tenemos entonces que hay tres filtros involucrados en la composición de esta imagen, y en la original (Imagen 1) hay 4, así que quedará un poco diferente, que es algo de lo que queríamos lograr. La siguiente imágen revela cómo se ven las imágenes en escalas de grises antes de ser compuestas a color falso:
Imagen 2: imágenes infrarrojas usadas para componer el color falso. Diferentes imágenes mapean la presencia de variedades de elementos en el complejo sistema de formación estelar.
Nuestro interés es tomar estas imágenes FITS y usarlas para poder componer imágenes de color falso, buscando los parámetros necesarios para visualizar los datos correctamente, y además con un fin estético.
Imagen 3: LDN1527 desde mi punto de vista. Se asignó el canal rojo R $\rightarrow$ f335m, el canal verde G $\rightarrow$ f444w, y el azul B $\rightarrow$ (f444w-f470n).
Ahora sabemos por ejemplo, en qué lugares espefícicamente hay más presencia de PAH, dados los clores que esté pintado. Por ejemplo en la siguiente imagen, la codificación de colores es la siguiente:
R $\rightarrow$ f335m
G $\rightarrow$ f444w
B $\rightarrow$ (f444w-f470n)
Por lo tanto, los tonos rojos de la imagen 3 corresponden a la presencia de PAH y CH4, muy comunes de encontrar en el material expulsado. Los filamentos azules corresponde a la presencia de hidrógeno molecular o H2 que es iluminado por la radiación UV del objeto central. Los otros colores son el resultado de la suma. Interesante y bonito :D
Existen 5 composiciones más, si simbolizamos los canales rgb como (i,j,k) = (0,1,2), podemos formar las siguientes imágenes usanda cada uno de sus órdenes:
(0,1,2)
(0,2,1)
(1,0,2)
(1,2,0)
(2,0,1)
(2,1,0)
¿Cuál es su favorita? La mía es la (2,1,0) y la (0,1,2). Si hacen click sobre cada una de las nebulosas, pueden descargar la imágenes ;)
Como el teorema del límite central es tan común en la naturaleza y aparece con tanta frecuencia cuando se levantan grandes cantidades de datos disponibles en nuestra era, que tener una función para ajustar una distribución gaussiana o normal no es una mala idea.
Me explico: supongamos que tenemos un set de datos que es de nuestro interés, y al visualizarlo notamos que podría ser descrito por un perfíl gaussiano. ¿Cómo obtenemos o extraemos los valores de dicha distribución, con el fin de estudiar sus parámetros?
Creemos una distribución artificial y veamos cómo entender dicha distribución, usando un puñado de puntos (100 mediciones) para poder caracterizar la muestra:
fromnumpy.randomimportseedfromnumpy.randomimportnormalimportmatplotlib.pyplotaspltimportnumpyasnp#celda magica%matplotlib inline
#semilla para reproduccionseed(40)#generamos datos con media cero, dispersion 1 y de tamaño 100centro=0desviacion=1plt.figure(figsize=(6,3))data=normal(loc=centro,scale=desviacion,size=100)_,_,_=plt.hist(data,18,label='distribucion generada')plt.legend(loc='best')plt.show()
Estos datos podrían corresponder a variados fenómenos físicos y/o describir el funcionamiento de algún proceso conocido de antemano. Supongamos que son reales y es imperante entenderlos y caracterizarlo adecuadamente.
Entonces, usaremos la librería scipy, particularmente la función optimize para crear una función que ajuste un perfil gaussiano descrito explicitamente, y los restos (la comparación entre la distribución y el modelo gaussiano) serán minimizados en el sentido de los mínimos cuadrados. Esto será logrado (ajustado o fiteado) usando una función de bondad de ajuste llamada chi cuadrado $\chi ^2$.
Vamos a ello:
deffit_gauss(X,guess,plot=False,large=[6,4],normed=True,xlabel='',Nbins=None,lw=3,fontsize=15,points=False):""" Ajusta una función gaussiana a una distribucion dada. Entrada: X: Distribucion. guess: Valores iniciales para realizar el ajuste (guess=[mu,sigma,amplitud]) plot: mostrar el ajuste. large: tamaño del plot. normed: Si se normaliza el histograma y la funcion. Salida: mu: Valor medio de la gaussiana. sigma: desviacion estandar del ajuste. amplitud: amplitud de la funcion. """fromscipyimportoptimizeimportnumpyasnpimportmatplotlib.pyplotasplt#Entendemos la distribución de entrada:(altura,bins)=np.histogram(X,bins=Nbins,density=normed)hist=np.array([(bins[i]+bins[i+1])/2.foriinrange(len(bins)-1)])#describimos explicitamente la función gaussiana:defgaussian(val,x):return(val[2])*np.exp(-0.5*((x-val[0])/val[1])**2)#describimos explicitamente la métrica de bondad de ajuste, chi cuadrado (chi2)defchi2(val,x,y):return(y-gaussian(val,x))**2#Asumiendo que los errores son 1x=np.linspace(np.min(X),np.max(X),Nbins)xi=np.linspace(np.min(X),np.max(X),1000)#realizamos el ajuste usando los minimos cuadrados.fit=optimize.leastsq(chi2,guess,args=(hist,altura))#obtenemos los parámetros calculados.mu=fit[0][0]sigma=abs(fit[0][1])ampl=abs(fit[0][2])#agregamos algunas funciones de visualización:ifplot==True:plt.figure(figsize=large)ifnormed==True:plt.ylabel(r'${\rm Normalized\ Amplitude }$',fontsize=fontsize)else:plt.ylabel(r'${\rm Amplitude }$',fontsize=fontsize)plt.xlabel(r'${\rm %s }$'%xlabel,fontsize=fontsize)
a,b,c=plt.hist(X,Nbins,density=normed,label='distribucion generada')ifpoints==True:plt.plot(hist,altura,'o--',color='black',label='datos ajustados')plt.plot(xi,gaussian(fit[0],xi),'-',color='red',linewidth=lw,label=' modelo gaussiano')#listocoreturnmu,sigma,ampl
Para ayudar a la convergencia de nuestro fit, "adivinaremos" los parámetros que podrían llegar a describir la distribución gaussiana, esto es normalmente llamado "guess". Usaremos los promedios de la distribución para obtener el $\mu$, la desviación estandar para obtener el $\sigma$, y la altura es el parámetro más laxo, usualmente lo fijo en 10 sin ningun análisis previo.
#Obtenemos el guessguess=[np.mean(data),np.std(data),10]#Aplicamos la función y obtenemos los parámetros de la distribución:mu,sigma,ampl=fit_gauss(data,guess=guess,plot=True,large=[8,4],normed=True,xlabel='distribucion\ generada',Nbins=18,points=True)#Definimos el factor de threshold:factor=2#preparamos el gráfico y ploteamos:plt.axvline(x=mu,color='red',)plt.axvline(x=mu+factor*sigma)plt.text(mu+factor*sigma,0.33,'$\mu+2\sigma$',rotation=90,fontsize=20)plt.axvline(x=mu-factor*sigma)plt.text(mu-factor*sigma-0.27,0.33,'$\mu-2\sigma$',rotation=90,fontsize=20)plt.legend(loc='best',fontsize=6)print('Valor mu original: ',centro)print('Valor sigma original: ',desviacion)print('Valor mu extraido: ',mu)print('Valor sigma extraido: ',sigma)print('Amplitud gaussiana: ',ampl)plt.show()
Valor mu original: 0
Valor sigma original: 1
Valor mu extraido: 0.06000778854169946
Valor sigma extraido: 0.9555102876405009
Amplitud gaussiana: 0.3969734189747305
Entonces, desde la función hemos obtenido parámetros similares desde los que fueron creados los datos sintéticos desde una media $\mu=0$ ($\mu_{fit} = 0.06$), con $\sigma=1$ ($\sigma_{fit} = 0.95$), y una altura de 0.39.
Se ve que los puntos negros que describen cada bin por separado, difieren bastante del modelo gaussiado utilizado (en rojo). Aún así, en promedio, los restos se minimizan y el ajuste se logra con cierto éxito. De hecho, es comprobable (¿tarea para el/la revisor/a?) que la distribución de los restos entre los datos y el modelo generan una nueva distribución gaussiana, y es por esto que el fit funciona. De hecho si los restos no fueran gaussianos, me preocuparía mucho el fit, independiente del aspecto que tenga.
Estas funciones se podrían hacer recursivas para caracterizar distribuciones aún más complejas dependiendo de los requerimientos, y por supuesto que, al generar datos con más puntos, la estimación será aun más precisa.
Veamos esto y finalicemos el caso de uso:
#usamos diferentes parámetros de entrada sólo para comprobar la función:centro=43245.567desviacion=200Ndatos=10000data=normal(loc=centro,scale=desviacion,size=Ndatos)#adivinamos dónde están, aproximadamente, los valores de ajuste.guess=[np.mean(data),np.std(data),10]#Aplicamos la función y obtenemos los parámetros de la distribución:mu,sigma,ampl=fit_gauss(data,guess=guess,plot=True,large=[8,3],normed=True,xlabel='distribucion\ generada',Nbins=30,points=True)plt.legend(loc='best')print('Valor mu original: ',centro)print('Valor sigma original: ',desviacion)print('Valor mu extraido: ',mu)print('Valor sigma extraido: ',sigma)print('Amplitud gaussiana: ',ampl)plt.show()
Valor mu original: 43245.567
Valor sigma original: 200
Valor mu extraido: 43245.03269244447
Valor sigma extraido: 199.7365006428819
Amplitud gaussiana: 0.0019831333256458026
Bueno, y si hasta aquí ya no resolviste tu duda, quizá lo que buscabas era una forma de tomar una distribución dada, y luego probar diferentes modelos, cosa que lo haga rápido y sin tantas preguntas, que me lo haga ahora yaaaaaa.
Se pueden usar librerias especializadas, como Fitter, veamos un ejemplo.
fromfitterimportFitterfromfitterimportget_common_distributionsplt.figure(figsize=(10,3))modelos=Fitter(data,distributions=get_common_distributions())#Ejecutamos el analisis modelos.fit()modelos.summary()
Vemos que existe un sumario visual de las estadísticas y modelos posibles de generación de una distribución. Los mejores indicadores son una distribución normal, para sorpresa de nadie, pero no se ve porque está debajo del siguiente modelo que ajusta a la perfección: la distribución gamma. Interesante, podríamos indagar en esto, pero lástima que está fuera de mis intereses justo ahora. Pero antes de irnos, asegurémoos de que los parámetros son correctos:
#Usando el método de minimización de la diferencia cuadrada de los errores y obtenemos el mejor modelof.get_best(method='sumsquare_error')
Como vemos, el mejor modelo es la distribución normal (norm), usando una media (loc) de $\mu=43243.15$ [alguna unidad], y un sigma (scale) de $\sigma=201.27$. Me parece suficiente para mis propósitos.
El telescopio espacial James Webb (JWST para los amiguis) ya está calibrado y apuntando a los objetos más interesantes e icónicos que su predecesor, el telescopio espacial Hubble (lanzado en el 1990) logró identificar y elevó imágenes con un misterioso atractivo hacia la cultura popular. Y las primeras imágenes que ha liberado hace ya algunos días ha establecido ciertas espectativas para los curiosos de estas verdaderas máquinas del tiempo llamadas telescopios.
Mucha gente en redes sociales ha esperado y replicado las imágenes que ha liberado la NASA de las bandas infrarrojas de su nuevo telescopio favorito. Así que me propuse obtener estos nuevos datos y ver qué era posible hacer con ellos. Luego de un rato, llegué al servicio de imágenes de misiones satelitales, desde donde pude obtener algunas de las imágenes de su cámara infrarroja cercana (NIRCAM). Ahora, sólo había que elegir un objetivo.
Una estrella moribunda
Una nebulosa planetaria es una nebulosa de emisión, un objeto astronómico emite luz dada la proximidad de un objeto central evolucionado (Una Enana Blanca) muy caliente, que calienta e ioniza el medio; y así expulsa o empuja las capas posteriores. En general son objetos simétricos alrededor de un eje. Su origen ilustra la muerte de una estrella y el abandono de sus capas más externas para dar paso al enriquecimiento del medio interestelar con elementos más pesados.
Justo como podriamos caracterizar la estructura de NGC 3132, por su estructura en forma de elipse cruzada por otra estructura de forma circular. Para comprender su origen, los elementos que la componen y su dinámica, este objeto ha sido observado por muchos telescopios y en variadas longuitudes de onda.
Con estas imágenes se confirma la naturaleza binaria de este sistema, donde la enana blanca (la estrella moribunda) ha ido expulsando masa de forma periodica mientras su compañera ayuda a mezclar los elementos, y produce simetría (en este caso).
Y es así como el JWST ha apuntado sus instrumentos a este objeto sideral, produciendo así varias imágenes científicas, y aquí hemos considerado tres de estás imágenes, obtenidas usando los filtros de la cámara NIRCam:
Fig 1, - Caracteristicas de los filtros montados en la NIRCam del JWST.
F090w, filtro de banda “mediana” (entre narrow y broad), centrada en los 0,9$\mu$m.
F187n, filtro estrecho centrado en los 1,87$\mu$m.
F212n, filtro estrecho centrado en los 2,12$\mu$m.
Imagen F090w
Imagen F187n
Imagen F212n
Nuestro interés es tomar estas imágenes FITS y usarlas para poder componer imágenes de color falso. Pero ¿Cuál sería la forma “correcta” de ensamblar una imagen de color? Mirando la Figura 1, podemos ver que en primera instancia, podríamos considerar seguir la lógica de longuitudes de ondas más largas al rojo, mientras que las longuitudes de onda más cortas al azul, lo que da el resultado de la figura 2.
Las capas externas de la estrella moribunda se muestran en rojo, mientras que la emisión verde es gas ionizado por la gran temperatura de la enana blanca central. Por otro lado, los anillos amarillos con forma elíptica representa las áreas donde el gas interno empuja las capas externas de este verdadero cadaver estelar.
Pero en realidad, ésta seria sólo una forma de visualizar estas imágenes para que nosotros, humanos con sentidos limitados, podamos entender los diversos matices y radiación que una compleja fuente de luz como esta puede emitir. Si consideramos que para crear imágenes de colores falsos se necesitan tres mapas de intensidad, podemos generar hasta 6 diferentes combinaciones. Todas válidas cuando se busca lo estético.
Entonces, si simbolizamos los canales rgb como (i,j,k) = (0,1,2), podemos formar las siguientes imágenes usanda cada uno de sus órdenes:
(0,1,2)
(0,2,1)
(1,0,2)
(1,2,0)
(2,0,1)
(2,1,0)
¿Cuál es su favorita? La mía es la (1,2,0) y la (1,0,2). Si hacen click sobre cada una de las nebulosas, pueden descargar la imágenes ;)
¿Saben? El asunto con escribir aquí es, en realidad, una forma de recordar las cosas que opino sobre materias específicas, y luego olvido porque, bueno, yo soy así.
Uno de mis pasatiempos más cuestionables (diría quizá algun psicólogo) es el repasar constantemente las cosas que di como ciertas o les tengo algo de confianza. Esto es necesario cada cierto tiempo porque las personas cambiamos a través de los años, maduramos, y nos damos cuenta que nuestra evaluación de ciertos parámetros necesitan ser repasados en función de la perspectiva que vamos ganando. Además, me interesan tantas cosas en este universo observable que muchas veces es necesario tomar desiciones apresuradas para poder seguir adelante (lo anterior no aplicar a los efectos de la cerveza sobre el cuerpo humano).
Es necesario seguir leyendo, estudiando, conversando, identificando sesgos cognitivos y ver cómo nos afectan de forma parcialmente invisible. Lamentablemente, ésta no es la conclusión de gran parte de la gente que he podido conocer. Mucha gente se queda con lo que le dicen en la infancia y son obligados a decir sostenidamente a lo largo de su vida, sin posibilidad a duda ni explicación alternativa. O si bien pueden superar esta barrera, saltan a la siguiente y quedan ahí, porque la segunda o las siguientes parecieran ser diferentes. Cuando alguien proclama que sabe algo, reniegan de las dudas y las tildan de malas, que la ignorancia es ser débil, vulnerable; siendo muchas veces exactamente lo contrario.
Entonces, acá escribiré un poco sobre por qué me considero Ateismo Agnóstico.
Después de pasar toda mi infancia y parte de mi adolescencia siendo un ferviente cristiano, de aquellos que pasaba su tiempo libre en la casa parroquial de Lorenzo Arenas (Concepción) y Hualpén; creo que era cosa de tiempo solamente para llegar individualmente a la conclusión del ateismo, o que no creo en la existencia de dioses. En ese entonces, mi ateismo provino de la experimentación de la realidad dentro de las iglesias y su desconexión con lo real: Se canta sobre un dios que vive entre nosotros y se manifiesta en todos los aspectos de la vida. Traté de verlo en todas partes, pero su ausencia siempre fue una constante. ¿Acaso era una mala persona por no percibirlo? ¿Cómo un dios tan poderoso puede confiar su existencia a la interpretación humana y no en la evidencia explicita de su existencia? Raro por lo bajo.
Fue complejo, pero confié en la conclusión que había llegado: no existía el dios del que me habían contado. Al principio fue dificil, ya que el cristianismo (y en particular el catolicismo) inserta en los creyentes la culpa como uno de los mecanismos fundamentales para no separarse del “camino de dios”. Se desarrolla la idea del infierno eterno y obviamente uno no quiere eso ni para uno ni para sus cercanos.
Además, esta decisión tampoco solucionaba el vacío existencial, esa angustia de sentir que nuestra existencia no es, potencialmente, fundamental ni destinada a algo. Esto último sólo se logra evitar con estudio y reflexión. Y vaya que es necesaria la reflexión, porque la realidad es aún más abrumadora cuando no crees que exista un dios.
Las proposiciones ateas y agnósticas.
Al conversar con otros autodenominados “ateos” se entendía que, en realidad, muchas veces era sólo otro nicho de apariencias, donde interesaba ir en contra de la iglesia o cualquer cosa que tuviera tintes sacros; o que simplemente les gustaba agredir las creencias de otras personas porque les parecían estúpidas. Esas personas se sentían “superiores” por no creer, pero bastaba cruzar algunas palabras para darse cuenta que no les interesaba comprender la realidad. Afirmar que no existen dioses era, de alguna forma, parte importante de su personalidad rebelde. Lo que siempre me llamó la atención de ellos era ¿cómo afirman algo sin evidencia? ¿Acaso los ateos son igual de dogmáticos que los cristianos?
Pero resulta que no es así, porque el ateismo no es dogmático, no es la declaración o afirmación de que no existen dioses, sino la negación de una creencia injustificada ante la falta de evidencia. ¿Por qué yo debería creer en dios? ¡demuestrenme ustedes que existe, luego les creo! Esto, en el pensamiento crítico, es llamado la carga de la prueba. Parafraseando a Carl Sagan: “Afirmaciones extraordinarias requieren evidencia extraordinaria”.
Por otro lado, están los agnosticos, que son personas que consideran que no puede ser demostrada la existencia o la no-existencia de deidades, ya que no existen evidencia suficiente para concluir alguna de las anteriores. El agnóstico cree que la existencia o no existencia de deidades no puede ser demostrada o no hay suficientes evidencias para confirmar una u otra posición. Ante la pregunta: ¿Sabes si existe dios? Un agnóstico dice: no sé; podrian ser muchos, uno, o no existir. Ésta afirmación les da a los agnosticos fama de despreocupados o de ser algo hippies.
Existen diversas corrientes filosóficas con definiciones bien detalladas sobre qué es el ateismo, el agnosticismo y sobre un sin fin de corrientes alternativas. Pero bajo mi perspectiva, lo fundamental aquí es entender que el saber y el creer son cosas y planos diferentes del conocimiento, y depende de nuestra honestidad intelectual averiguar cuál es el dominio en el que estamos inmersos.
El siguiente gráfico tomado de la página el diferenciador resulta ilustrador:
Figura 1: Plano cartesiando de las variables (saber,creer). Cuatro posibilidades se abren paso y el universo se complejiza, para variar.
Ambas dimensiones independientes (saber, creer) pueden ser representados en el plano cartesiano y cuantificarse a lo menos 4 zonas diferentes independientes; por ende ser ateo agnóstico es una respuesta plausible ante la vida. Yo me considero Ateo agnóstico porque considero que el ateísmo y el gnosticismo son planos diferentes de un mismo suceso.
Ante la pregunta ¿CREES en dios? Yo digo no, no creo. No veo evidencia de él ni ninguna manifestación en toda la historia, por lo que me considero ateo. Mi ateismo proviene desde la experimentación de la realidad. Ante la pregunta ¿SABES si existe dios? Yo respondo no sé, no tengo cómo comprobar que existe, o que no existe, por lo que me considero agnóstico.
El ateismo es una opinión, pero el agnostiscimo es la conclusión de vivir en un mundo sin fronteras claras, por lo menos para un simple humano.
Lucy no tenía nombre, pero merecía uno. La encontré justo dentro de una nube oscura infrarroja (IRDC en inglés), las cuales son regiones muy densas y frías dentro de regiones masivas de formación estelar. Estas nubes son de gran interés dado que porque se piensa que las estrellas masivas (sobre 8 masas solares :o ) se forman en regiones con estas condiciones.
Es posible ver en las imágenes de color falso la densidad de estas nubes dado que esconden las estrellas que están por detrás. Todo el campo está poblado, menos donde están distribuidas estas nubes negras. Hasta las estrellas que están cerca de estas nubes parecen más enrojecidas o extintas de lo normal.
Está localizada a 1 grado de distancia de la nebulosa Trífida, la cual he estudiado bastante ultimamente, y famosa además por aparecer en la portada del disco Islands de la banda británica King Crimson.
En los alrededores de esta estrella existen varias fuentes con indicadores de formación estelar, como Masers. así que tiene sentido pensar que se trata de un objeto joven estelar (YSO en inglés).
Esta estrella está en etapas tempranas de formación, es por eso que dada su gravedad, atraerá a toda la masa circundante y peleará por conseguir más masa del medio que sus posibles hermanas estrellas, en un proceso que se llama acreción competitiva. Pero aún no están claros los mecanismos de formación ni el método con el cual alcanzan su masa final.
09 de Abril del 2010
23 de Septiembre del 2015
En su serie de tiempo se puede apreciar que en el año 2010 aparece muy débil dentro de la IRDC y va subiendo su magnitud aparecen muy lentamente hasta alcanzar el 14.5 [mag], provocando una gran amplitud total $\Delta K_s = 2.416\pm0.092$, digno de una estrella tan alborotada como lo son las fuentes estelares en sus etapas tempranas.
Dado el gradual incremento en el brillo de esta estrella, ha sido clasificada en la categoría fader, del cual imagino que debo hacer una descripción dada la carencia de información sobre esa terminología hasta el momento.