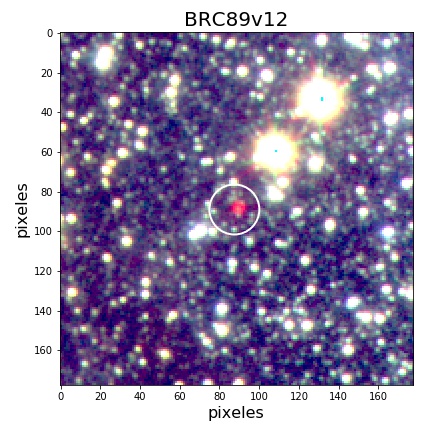
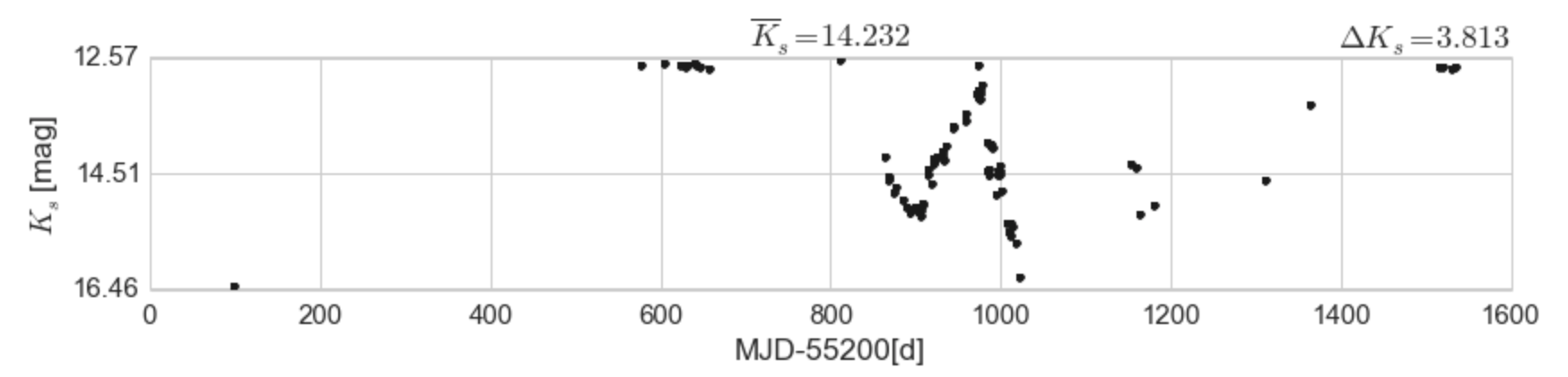
Ésta fue la fuente estelar que me desconsertó en los primeros momento de investigar el vasto campo de las estrellas variables: BRC89v12. Su nombre es debido a que es la estrella variable número 12 de la Nube de bordes brillantes 89 (Bright-Rimmed Cloud, BRC89), perteneciente a un grupo de Regiones de formación estelar muy conocido, el grupo de la nebulosa de La Laguna.
Las llamadas Bright-Rimmed Clouds son regiones de gas que están asociadas a Regiones de formación estelar (SFR en inglés) masivas y son producidas frecuentemente por frentes de choque producto del viento estelar que proviene de estrellas masivas OB a su alrededor. Otros mecanismos con los que podrían ser producidos es por explosion de Super Novas u otra interacción que produzcan formación estelar dada la compresión del medio interestelar superando los parámetros de Jean.
Esta estrella no era desconocida para la literatura, ya que ha sido estudiada y clasificada como una estrella con líneas de emisión de H$_\alpha$ por allá en el 2002, en un artículo publicado por (Ogura et al. 2002), esto significa que esta estrella sigue en proceso de formación y actualmente está proceso de acreción.
Su amplitud fotométrica es GIGANTE y hay muchas más del mismo tipo alrededor de esta nube, por lo que pensé que encontrarse con este tipo de variabilidad era normal entre las estrella. Ay de mi que pensé eso en el pasado. Pero no, esta variabilidad no es normal, y es una señal clara del proceso llamado Acreción episódica, donde el disco de acreción de la proto-estrella se desprende en trozos y la acreción no es constante. Los cambios drásticos de su brillo suceden cuando el proceso de acreción comienza y se detiene.
Cuando logras apartarte de la contaminación lumínica, las estrellas que habitan el cielo son abrumadoras. Muchos, incontables puntos brillantes que ostentan tenues y centellantes colores se posicionan dispersas en el centro galáctico y a lo largo del disco de nuestra Vía Láctea. Luego de algunos días ya será posible reconocer estructuras y constelaciones (la gente dice que hasta escorpiones es posible ver). Hasta que de pronto un puntito particular del cielo cambia su brillo, aumentando o disminuyendo de forma dramática: ¿Qué ha pasado?
Sea lo que sea que haya pasado, la explicación menos probable siempre será que fue un alien, un OVNI o vida extraterrestre. Resulta que el universo esta lleno de luces extrañas que cambian su brillo a lo largo del tiempo, y lo más probable es que nos hayamos topado con una estrella variable, una fuente estelar que cambia su brillo superficial mientras el tiempo pasa. La verdad que son muy comunes, existen de muchos tipos y hoy explicaré cómo podemos llegar a saber tantas cosas sobre estos puntitos luminosos.
Figura 1: Animación que muestra el evidente brillo variable de la candidata a estrella Nova Del2013 (PNVJ20233073+2046041). La imagen muestra dos fotos del mismo campo estelar, antes y después del misterioso episodio.
Bolas de gas en equilibrio quemándose a millones de kilómetros de aquí
Una estrella es una gigantezca esfera de gas, la cual ha alcanzado las condiciones físicas necesarias para que en su centro se desencadenen una serie de reacciones nucleares a través de la fusión nuclear, las cuales liberan y transmiten energía hacia el exterior en forma de radiación electromagnética (luz y calor). Las estrellas poseen su característica forma esférica dado que existe un balance entre dos fuerzas fundamentales: Primero está la gravedad, la cual es generada por la masa de la estrella y actua atrayendo y comprimiendo el gas hacia el centro. Y luego está la presión provocada por el mismo gas, que al estar a una temperatura elevada se expande y genera presión sobre su entorno, como en un globo de aire caliente (asumiendo que han visto uno, personalmente yo no). Cuando una estrella cumple esta condición de equilibrio, se dice que está en equilibrio hidrostático y la estrella adoptará una forma esférica estable. Usando flechas de colores, la figura 2 muestra que la presión se genera del centro hacia afuera, y la gravedad desde la superficie hacia el centro. Ambas llegarán a un punto donde se contrarrestarán hasta alcanzar su LOGICA geometría.
Figura 2: Esquema del balance de la presión con la gravedad. La gravedad tratará de comprimir todo el material hacia el centro del sistema, y la presión tratará de expandirlo, generando esta esfera de gas incandescente.
La estrella del sistema solar
El Sol es nuestra estrella, y es la fuente de energía que sostiene la vida en la tierra. Es el objeto que contiene más masa y produce mayor cantidad de radiación en estas vecindades galácticas. Pero no es sólo por su luz que es reconocido, sino que también por su gravedad, haciendo que polvo, piedras y bolas de gas cercanas giren a su alrededor e interactuen entre ellas para la formación de diferentes estructuras, como planetas o asteroides.
La raza humana tempranamente entendió que el sol jugaba un papel principal en su día a día, siendo elevado a la categoría de dios en gran parte de las culturas originarias, llegando al punto de provocar pánico colectivo cuando su brillo disminuía sin previo aviso, como en un eclipse de luna. Que lata ser un maya y de repente pum, eclipse.
La observación prolongada de la posición relativa del sol en el cielo, y ver cómo afectaba a la naturaleza permitió distinguir las estaciones, y con ello a los cultivos selectivos, los pueblos sedentarios, las grandes ciudades y de un momento a otro la explosión demográfica. Pasando por toda clase de invenciones relevantes y avances científicos para desvanecer la incomodidad de no saber qué era lo que realmente pasaba en el cielo, buscando explicación a ese conjunto de fenómenos regulares que se apreciaban en el movimiento de los planetas, y qué tenían que ver todos esos otros puntos que no parecían para nada soles.
Video 1: Pumba le pregunta a Timón qué son las estrellas. Como Timón no sabe, pero le incomoda la ignorancia, decide inventar una historia antes que asumir la verdad.
¿Todas las estrellas son como el sol? (spoilert alert: nope)
Toda la cultura y las aventuras de la humanidad están confinadas en nuestro sistema solar y aún así, siento ser yo el que te lo diga, pero el sol es una estrella promedio, una más del montón de estrellas del grupo de baja masa. Nuestra estrella tiene un radio de 697.000 [Km], a una distancia de 149.597.870.700 [metros] = 1,49$\times$10$^{8}$ [Km], y una masa de 1,99$\times$10$^{30}$ [Kg] (un uno seguido de 30 ceros), casi el 99,8% de la masa de todo nuestro sistema planetario, y aún así, es un cuerpo de baja masa D:
Esta afirmación es el resultado del gran número de estrellas que se han observado a lo largo de los años, tanto dentro de nuestra galaxia como en galaxias vecinas. Hemos comparado todas estas estrellas con el sol y nos hemos dado cuenta que en el universo hay estructuras casi inimaginablemente más grandes. Aún así, la humanidad valora al Sol, y lo usaremos como referencia. Has demostrado ser una estrella tranquila y calurosa, así que te usaremos como una regla cósmica y usaremos como unidad básica:
la Masa Solar $M_{\odot} := 1,99\times10^{30}\ [Kg]$
El Radio Solar $R_{\odot} := 697.000\ [Km]$
la Luminosidad Solar $L_{\odot} := 3,82\times10^{26}\ [Watts]$
La unidad astronómica $[UA]:= 1,49\times10^{8}\ [Km]$
Sabiendo esto, ahora podremos hablar de otras estrellas usando como referencia las proporciones del sol ${M_{\odot}, R_{\odot}, L_{\odot}}$.
Entonces, en esta búsqueda de estudiar y comparar estrellas, se han encontrado toda una gama de diferentes escenarios, y se han definido distintas formas de clasificación, siendo la más importante la clasificación por tipo espectral, donde las estrellas se arreglan en base a sus temperaturas superficiales (o efectivas), y se les asigna una clase de tipo espectral ('O', 'B', 'A', 'F', 'G', 'K', 'M'). Diferentes clases poseerán diferentes temperaturas efectivas, las cuales también tiene relación con el color superficial. Si se preguntan por qué se eligieron esas letras, es porque este tipo de clasificación estelar está basado en la llamada clasificación de Harvard.
La siguiente tabla compara las propiedades de estrellas clasificadas en distintas clases espectrales, usando como base las unidades solares:
Clase
Temperatura
Color
Masa
Radio
Luminosidad bolométrica
O
≥ 33.000 K
azul
≥ 16 M☉
≥ 6,6 R☉
≥ 30.000 L☉
B
10.000–33.000 K
azul a blanco azulado
2,1–16 M☉
1,8–6,6 R☉
25–30.000 L☉
A
7.500–10.000 K
blanco
1,4–2,1M☉
1,4–1,8 R☉
5–25 L☉
F
6,000–7,500 K
blanco amarillento
1,04–1,4 M☉
1,15–1,4 R☉
1,5–5 L☉
G
5.200–6,000 K
amarillo
0,8–1,04 M☉
0,96–1,15 R☉
0,6–1,5 L☉
K
3.700–5.200 K
naranja
0,45–0,8 M☉
0,7–0,96 R☉
0,08–0,6 L☉
M
≤ 3.700 K
rojo
≤ 0,45 M☉
≤ 0,7 R☉
≤ 0,08 L☉
Además, a modo de comparación visual, la figura 3 muestra estrellas clasificadas en diferentes tipos espectrales. De forma visual es posible relacionar sus propiedades, como el tamaño, la masa y su color superficial, este último es muy importante para definir la temperatura superficial de la estrella, que se mide en Kelvins, por eso la letra [K] que la acompaña.
Figura 3: Relación entre el color y el tamaño de estrellas de diferentes tipos espectrales. El sol pertenece al tipo G, o también llamada Enana Amarilla.
Por ejemplo, la estrella que ostenta el record de más masiva habita la Nebulosa de la Tarántula, en la Gran Nube de Magallanes, y se llama R136a1, con una masa estimada $M=265M_{\odot}$, o sea que esta estrella tiene 265 veces la masa de nuestro humilde Sol. R136a1 es una de las estrellas 'O', las más grandes, azules, luminosas y de corta vida (algunos millones de años).
¿Cuál sería el tipo espectral del sol? ¿Y dónde estaría posicionado aproximadamente en la figura 3?
Lo interesante de esta clasificación es que si construimos una representación visual (aka, un gráfico) donde ordenamos las estrellas con respecto a su color (de azules a rojas) y luminosidad (más brillantes a menos brillantes), podemos ver que existe una coherencia, la cual nos habla del estado evolutivo de estas estrellas. El siguiente video toma un campo estelar muestra este orden de una manera magistral:
Video 2: Un campo estelar muestra muchas estrellas aparentemente no relacionadas entre si, pero cuando las estrellas se ordenan, primero por color y luego por lo brillante, nos damos de cara con el diagrama HR.
El diagrama antes mostrado, se conoce popularmente como el Diagrama de Hertzsprung-Russell o diagrama HR para no gastar tanto lápiz. Hay diferentes versiones del diagrama HR, pero todos apuntan a la caracterización del estado evolutivo de las estrellas en estudio. Dependiendo de las características de las estrellas (principalmente la masa), éstas recorrerán diferentes lugares del diagrama HR.
La figura 4 es muestra un diagrama HR, el cual ilustra en qué posición del diagrama se localizan estrellas con diferentes colores, luminosidades, masas, tipo espectral, y también se estima el tiempo aproximado de vida que poseen cada uno de esos puntitos luminosos. Es posible ver que la mayor parte de las estrellas están distribuidas a lo largo de la llamada Secuencia principal. Esta secuencia se caracteriza por contener estrellas que, en ese momento de sus vidas, están fusionando hidrógeno (el elemento más abundante en las estrellas) para convertirlo en Helio a través de la fusión nuclear, particularmente usando la cadena protón-protón. Justamente aquí, en esta secuencia es donde vive nuestro Sol, por lo que se puede deducir que hay muchas, muchísimias estrellas similares a nuestra querida bola nuclear.
Figura 4: Diagrama Hertzsprung-Russell comparando los parámetros físicos de estrellas. Las estrellas han sido ordenadas en Temperatura en el eje horizonral, y por su brillo en el eje vertical.
Las estrellas cambian a través del tiempo
Conforme pasa el tiempo, las estrellas van evolucionando y moviéndose por el diagrama HR. Esto implica que sufrirán diferentes procesos físicos que provocarán cambios en sus propiedades (cambios de temperatura, tamaño, luminosidad, pérdida de masa, etc) mientras se aproxima su muerte. Cuando una estrella particular sufre estos cambios, es donde se puede romper la condición de equilibrio hidrostático, haciendo que las estrellas puedan hacer visibles sus inestabilidades a través del cámbio de su brillo. Una de las grandes misiones de la astronomía del siglo XXI es caracterizar los cambios de brillo que pueden sufrir mientras las estrellas se mueven por el diagrama HR, para así poder entender qué le pasa.
Supongamos que cada uno tiene a disposición un telescopio para explorar el cielo. Si en vez de observar directamente con él, montamos una cámara fotográfica, podríamos tomar susesivas fotos a lo largo del cielo y unirlas para construir un mapa nocturno, o también se podrían tomar muchas fotos de una misma región celeste y ver cómo las fuentes luminosas se comportan a través del tiempo. Al comparar esas imágenes, es posible que veamos fuentes que cambien su luminosidad, de manera regular, irregular o que sencillamente que aparezcan y desaparezcan.
A modo de ejemplo, en la figura 5 se muestra un campo estelar que ha sido observado en 4 oportunidades diferentes. Dentro del círculo rojo se señala una estrella que cambia su brillo.
Figura 5: Ejemplo de un mismo campo estelar observado en diferentes fechas (épocas). En el círculo rojo del centro se muestra una fuente que cambia su brillo a lo largo del tiempo. Las imágenes fueron tomadas con el telescopio VISTA, ubicado en Paranal. Archivo personal (siempre quise escribir esto).
¿Qué le pasa a esta estrella? Imposible saberlo sin información adicional. Pero partamos simplificando el problema con una pregunta fundamental: ¿Es normal que la luminosidad de las fuentes astronómicas cambie a lo largo del tiempo? Para tener una pista, podemos examinar nuestra estrella más cercana, y ver si sufre de algún tipo de cambio de luminosidad, que no sea provocado por un eclipse.
De nuevo el sol: ¿una estrella variable?
El sol no es una bola de gas tan estable como nosotros la percibimos. Está muy bien documentado que en la superficie del sol aparecen manchas oscuras o manchas solares con regularidad, que obecede el llamado ciclo solar. Este ciclo se caracteriza por tener una duración de alrededor de 11 años, donde las manchas solares aparecen progresivamente, alcanzando un número máximo en la superficie y luego desaparecen, comenzando nuevamente el ciclo. Esta aparición/desaparición de manchas está asociado a la variación del campo magnético de nuestra estrella.
Contraintuitivamente, se conoce que el máximo de brillo del sol aparece cuando el número de manchas es máximo. Y es mínimo cuando desaparecen casi por completo. Esa variación de intensidad, medida en energía emitida por superficie ([Watts/metro cuadrado]) sin embargo, es de tan sólo un 0.1% (1365,5-1367 $[W / m^2]$, en relación a la constante solar $K=1366\ [W / m^2]$) por lo que la variación producida por las manchas es casi despreciable. La figura 6 muestra la evolución de la superficie de nuestro sol a lo largo de 11 años.
Figura 6: El ciclo solar muestra la evolución de las manchas solares a lo largo de los años.
Además, nuestra querida bola de gas incandescente es la protagonista de diferentes eventos eruptivos y explosiones que emanan grandes cantidades de materia al espacio circundante. Gran parte de estos eventos suceden en las regiones activas asociadas a manchas solares, donde emergen intensos campos magnéticos de la superficie del Sol, eyectando masa coronal. Estas fulguraciones solares tiene una escala de tiempo muy cortas (astronómicamente hablando) de tan solo minutos. En el siguiente video, es posible ver un evento eruptivo en nuestro sol.
Video 3: Un timelapse del sol muestra la magnitud que éstas repentinas erupciones pueden tener.
Las escala de distancias y la detección de la variabilidad
Todas esas manchas solares sólo modificaron la luminosidad del sol en un 0.1%. Y la mala noticia es que este mísero porcentaje sólo es detectable porque nosotros estamos cerca del sol. Recordemos que nosotros sólo a 149.597.870.700 metros = 1,49$\times$10$^{8}$Kilometros = 1 UA. Alfa Centauri, el sistema estelar más cercano, está sólo a unos pasos más allá, a 276.363,5 [UA], y así las distancias van aumentando exponencialmente hasta convertirse en números astronómicos. Ni siquiera es conveniente hablar ya de estas distancias en [UA], para eso se usa los años luz (lys) y el parsec (pc).
Aquí debemos hacer una pausa y pensar qué implica estar lejos de las fuentes. Destaco dos ideas principales:
La variabilidad de una fuente puede deberse a un proceso físico que ocurre en la fuente. ¿Verdad? Algo pasó dentro del sol, y gatilló esos poderosos campos magnéticos. Esta fue la causa del cambio de su brillo.
Por el hecho de estar muy lejos de las fuentes, es muy difícil poder medir con exactitud todos los procesos físicos involucrados.
Consideremos una Galaxia, como por ejemplo las galáxias de los ratones, las cuales se encuentran a una respetable distancia de 89 Megaparsecs $= 2,746\times10^{21} [Km]$ $= 1,83\times10^{13} [UA]$. A esa distancia, nos perderemos gran parte de los procesos estelares, sólo por mencionar algo.
Considerando todos estos aspectos, nuestra premisa será que todas las fuentes estelares son variables, pero si observamos lo suficiente. Es decir, si contamos con equipamiento con resolución y el tiempo necesario para registrar dicha fuente, se podrá caracterizar algún tipo de variación de luminosidad, dejándonos así inferir resultados a partir de dicha medición.
Ya bueno: ¿y cuántas fuentes luminosas variables existen?
A lo largo de la historia, muchos astrónomos, astrónomas e instituciones han observado toda clase de estrellas variables catalogado demasiados tipos como para ser nombrados aquí. Hay unas, por ejemplo, que se llaman estrellas RR Lyrae, las cuales sufren variaciones de brillo extremadamente regulares, y se estima que son estrellas relativamente viejas (). La siguiente imagen muestra cuántas de ellas conviven y centellean en un cúmulo globular.
Cada sub-tipo de estrella variable es un potencial tema de estudio, y donde el dilucidar sus misterios, el mecanismo por el cual sufre estas variaciones y el momento evolutivo que se encuentra son preguntas que aún se discuten y esperamos que pronto se resuelvan dada la ola de datos que se están observando y que se obtendrán con la apertura de la nueva generación de telescopios, como el GMT (Observatorio Las Campanas, región de Atacama) y el ELT (Observatorio Paranal, region de Antofagasta).
Así que mejor consultaremos el arbol de la variabilidad y toda su complejidad :D, de aquí en adelante, usaré árbol para ir hablando de diferentes fuentes que cambian su brillo.
Figura 8: Árbol de la variabilidad", el cual fue sacado de L. Eyer & N. Mowlavi.
La astronomía es sinónimo de imágenes asombrosas y siderales, literalmente fuera de este mundo. Composiciones a todo color que nos recuerdan que el universo está lleno de estructuras increibles, y conduce a la reflexión sobre nuestra realidad así como también del lugar que nos corresponde en el universo conocido. El correcto análisis de estas imágenes nos permite extraer información crítica desde la luz que emiten esos puntitos brillantes que habitan el cielo. A través de la física y sus artilugios matemáticos somos capaces de leer la luz entre lineas, para así comprender los secretos de quienes producen esta radiación: estrellas, galaxias, sus grupos...además de burbujas y marañas de gas y polvo, como las piedras que las orbitan.
La estética de la astronomía explica a sus multitudinarios y curiosos seguidores, despertando una de las dudas más comunes: ¿los colores de las imágenes son reales? ¿o son parte del malvado fotochop de la NASA con el fin de controlar nuestra vida?. Colorear imágenes es un proceso bien conocido, teniendo bases en el proceso biológico de cómo los humanos percibimos el color y cómo se entiende esta información de forma digital. Desde esta premisa, en las siguiente líneas haré el esfuerzo de unir todos estos cabos, cómo (des)componer una imagen y mostrales la forma de colorear una imagen astronómica.
El ojito humano y el color RGB.
El ojo humano es el resultado de millones de años de evolución en los cuales su sistema óptico se adaptó a la luz del Sol, nuestra bola de gas favorita. Este sistema óptico recibe y canaliza la luz hasta unas celulas especializadas fotosensibles, llamadas conos y bastones. Según wikipedia Los bastones se activan en condiciones de baja luminosidad. Los conos, por su lado, se ven estimulados en entornos con mayor iluminación y nuestros ojos están poblados por tres variedades diferentes: conos rojos, verdes y azules; sensibles a la luz visible con la cual se apellidan.
Esta sensibilidad particular a ciertos colores no es (taan) antojadiza, pasa que el sol emite muchos tipos de luz, pero la radiación que alcanza la tierra con mayor intensidad contiene estos colores, y a esto se le llama *espectro visible*, luz visible, o simplemente luz. Pero hay muchas otras variedades de luz las cuales son representadas en el rango electromagnético, que va desde las ondas de radio a los rayos gamma. Pasó que el sol emite mucha luz en el rango visible, el ojo humano se adaptó a esta radiación lo largo de su existencia y por eso vemos los colores del arcoiris. Esta es una idea muy poderosa, que nos lleva a pensar cómo se desarrollarían los detectores de radiacion (a.k.a. ojos) de seres que podrían habitan planetas con estrellas que emiten diferente luz, o también como la inexistencia de luz hace que no se desarrollen tales detectores. La siguente imágen muestra el rango electromagénico y su comparación de la luz que existe versus la luz que podemos observar, la luz visible.
Cuando la luz de una fuente luminosa incide sobre un objeto, absorbe ciertos colores y refleja otros. Es esa luz que hace rebotar un cierto objeto la que alcanza nuestros ojos y activa los diferentes conos en proporciones establecidas por los nervios ópticos, lo que nuestro cerebro interpreta como "un color". Simplificando todo, nuestro cerebro tiene 3 colores básicos y todas sus posibles proporciones para colorear nuestra realidad: rojo, verde, azul y sus conocidos mundialmente como RGB (del acrónimo inglés Red, Green, Blue). Estos colores clásicamente se conocen como colores primarios, ya que a partir de esta triada es posible obtener por completo el rango de colores del arcoiris.
Y ya que estamos aquí, es interesante señalar que de hecho vemos aún más colores que los que viven en la luz visible. El color Magenta es un claro ejemplo de esto, ya que no existe luz de este color con una longuitud de onda asociada en el mundo real. Esto significa que este color existe solo en nuestros cerebros, y es la interpretación de la superposición de dos diferentes longuitudes de onda de luz incidente. El siguiente video retrata de mejor manera lo que acabo de explicar:
Las imágenes son importantisimas en el día a día y ya son de uso cotidiano, al punto que ya no es necesario cuestionarse qué son en realidad y cómo pueden llegar a usarse para determinar misterios. Tan exitoso ha sido la integración de las imágenes a nuestro vertiginoso estilo de vida que muchas personas ignoran el hecho que son sólo un gran arreglo de números interpratados para que se parezcan lo más posible a lo que nosotros vemos: un instante congelado en el tiempo.
Las primeras imágenes se remontan al año 1839 gracias al daguerrotipo, el cual consistía en placas de cobre con películas de plata, que las convierte una superficie fotosensible, colectora de luz. Antes de esto había que ser buen dibujante para registrar los relieves y cráteres de la luna como hizo Galileo. Los métodos fotosensibles fueron perfecionandose a lo largo del tiempo, pasando por muchos formatos a lo largo de las décadas, como La placa fotográfica y cintas magnéticas. Hasta 1969, año en el que se desarrollaron los detectores electrónicos fotosensibles CCDs que cada uno de nosotros tiene en su teléfono, y que el 2009 (¡luego de 40 años!) les dio el novel de física a sus creadores Willard Boyle y George E. Smith.. Fue aquí donde se introdujo y popularizó el pixel como la undad básica de una imagen digital. Cada imagen, fotografía o contenido gráfico digital está hecho de pixeles, y de forma similar a los conos de nuestros ojos, cada uno de estos pixeles contiene 3 canales de color: rojo, verde y azul (o RGB). Combinando las intensidades de estos diferentes colores cada pixel puede motrar toda la gama de colores posibles, emulando así la lógica del ojo humano y creando la transición análogo/digital de la imagen.
En términos computacionales, podremos entender una imagen como un cubo de datos de (Pixeles$_{alto}\times$ Pixeles$_{largo}\times 3$). Para entrar un poco más en detalle y hagamos una biopsia a una imagen, usaremos el lenguaje de programación Python en su versión 3, que ya estamos usando pero no te diste ni cuenta. Para que funcione como corresponde, es necesario importar las funcionalidades básicas y librerías con las cuales visualizaremos todo:
#importamos librerias y cositas utiles%matplotlib inline
importnumpyasnpfrommatplotlib.pyplotimportimreadfromscipy.miscimport*fromscipyimportndimageimportmatplotlib.pyplotaspltfromPILimportImage#definimos algunos parametros:Dh=(6,4.5)fz=12
Con todo esto ya funcionando, leeremos una imagen de la estructura de una nube; imagen que fue capturada mientras el sol se estaba poniendo, dándole su color rojizo:
plt.figure(figsize=Dh)Nubes=imread('IMG_9164.JPG')#Miramos las dimensiones de la imagen:dimensiones=Nubes.shapeprint("Dimensiones de la imagen:")print("(alto, largo, canales) =",dimensiones)plt.imshow(Nubes)plt.xlabel('pixeles',size=12)plt.ylabel('pixeles',size=12)plt.show()
Dimensiones de la imagen:
(alto, largo, canales) = (2848, 4272, 3)
La información de las dimensiones arriba desplegada nos dice que la imagen tiene 2848 pixeles de alto, 4248 pixeles de largo y que está compuesta por tres arreglos de datos, que son los canales de color; cada uno de estos canales posee las mismas dimensiones antes estipuladas.
Es así que la imagen desplegada, para cada valor Nubes[x,y] existen 3 valores de rojo, verde, y azul, los cuales en conjunto muestran el color. En el caso anterior supongo que el color rojo domina dadas las virtudes del arrebol de la tarde. Pero no nos quedemos en supuestos y veamos la contribución de cada canal en el color de nuestra nubecita roja. Seleccionaremos todas las filas de pixeles, y 900 columnas en la parte central de la imagen, así nuestra nueva imagen Nubecita[x,y] tendrá 2848x900 pixeles y sus 3 canales RGB. Seleccionaremos cada canal de color por separado para así visualizar la contribución de cada uno de estos colores ejerce en la imagen "Original":
#Separamos cada canal 0,1 y 2 de forma individual desde subImagenNubecita=Nubes[:,2000:2900]dimensiones=Nubecita.shapeprint("Dimensiones de la imagen:")print("(alto, largo, canales) =",dimensiones)r=Nubecita[:,:,0]#Canal rojog=Nubecita[:,:,1]#Canal verdeb=Nubecita[:,:,2]#Canal azulf,ejes=plt.subplots(1,4,figsize=Dh,sharey=True)ejes[0].imshow(Nubecita)ejes[0].set_title("Nubecita")ejes[1].imshow(r)ejes[1].set_title("canal rojo R")ejes[2].imshow(g)ejes[2].set_title("canal verde G")ejes[3].imshow(b)ejes[3].set_title("canal azul B")plt.tight_layout()plt.savefig("Ver_canales.png",dpi=300)plt.show()
Dimensiones de la imagen:
(alto, largo, canales) = (2848, 900, 3)
En el esquema anterior, las imágenes de cada canal están "coloreadas falsamente", esto quiere decir que sus colores representan un código y una escala para que podamos distinguir sus contribuciones (en este caso sería en las partes...¿amarillas, verdes?, lo más brillante), o donde no la hay (las partes azules y oscuras). Normalmente estas imágenes se les representa en escala de grises, pero bueno, ese era el color por defecto, ná que hacerle ¯\_(ツ)_/¯.
Ahora, podemos ver cuánto aporta a la imagen cada canal RGB de forma individual. Es fácil darse cuenta que la contribución del canal rojo R está en todas partes, domina las estructuras y los valores de la imagen Nubecita. Por otro lado, el canal azul mayoritariamente no aporta, y solo está presente en la parte central, donde casi no hay nubes y el cielo está de fondo. Desde aquí debo destacar dos aspectos:
Desde la correcta suma de las imágenes R+G+B es posible obtener la imagen Nubecita de vuelta.
Las imágenes de canal son ejemplos perfectos de una imagen producida por un "filtro optico", que muestra la contribución de luz en un rango definido.
Hacer listas es mi pasión.
Una propiedad fundamental que se desprenden de los filtros es que ven cosas diferentes al observar la misma fuente de luz. Por ejemplo si quisieramos describir la forma de la nube imagen nubecita, sería mejor estudiar el canal rojo, ya que es más sensible a la luz que se emite desde las nubes. Por otro lado, podríamos usar el filtro azul para saber dónde no hay nube, por decir algo jajaja, el filtro malo.
Es por eso que una fuente luminosa se estudia en muchos filtos, ya que la cantidad y tipo de luz de cada filtro se pueden usar para resaltar distintos elementos de un mismo fenómeno.
¡Ya tenemos nuestras primeras herramientas! ¿Para qué podrían llegar a servir? Bueno, la manipulación de imágenes es una práctica recurrente en el día de hoy y muchas son sus aplicaciones, no solo para hacer memes. Lo importante aquí en mi humilde opinión, es darse cuenta que las imagenes sólo son números en un arreglo de datos dispuestos a ser ordenados como bloques, cual Legos. Entenderlos apropiadamente nos da muchas posibilidades, por ejemplo veamos una imagen de la luna que hice hace un tiempo cuando habia una conjunción con el planeta Júpiter, que se nota como un pequeño punto brillante al lado contrario de la luna y le haremos un corte (o un "Zoom digital" que le llaman a veces) al satélite natural:
plt.figure(figsize=Dh)Luna=imread('IMG_9206.JPG')plt.imshow(Luna)plt.title("Imagen original",size=12)plt.xlabel('pixeles',size=12)plt.ylabel('pixeles',size=12)plt.show()subImagen=Luna[500:1050,650:1200]dimensiones=subImagen.shapeprint("Dimensiones de la imagen recortada:")print("(alto, largo, canales) =",dimensiones)plt.figure(figsize=(6.5,6.5))plt.imshow(subImagen)plt.title("Imagen recortada",size=12)plt.xlabel('pixeles',size=12)plt.ylabel('pixeles',size=12)plt.show()
Dimensiones de la imagen recortada:
(alto, largo, canales) = (550, 550, 3)
O podríamos también crear nuevas imágenes a partir de otras. En gran parte de los casos esto será posible sólo si las imágenes a combinar poseen las mismas dimensiones. Si la condición anterios se cumple, podemos llegar y sumar las imágenes diréctamente. Por ejemplo, y sólo por capricho, agregaré otra imagen de la luna en fase menguante, además de rotar la imagen 1 en 180 grados, y sumaremos todo en una gran imagen. No se diga más.
#Leemos la nueva imagen de la luna para componer:creciente=imread('IMG_7793.JPG')plt.figure(figsize=Dh)plt.imshow(creciente)plt.title("Luna creciente",size=15)plt.xlabel('pixeles',size=12)plt.ylabel('pixeles',size=12)plt.show()#Rotamos la imagen original de la lunaLuna_rotada180=Image.fromarray(np.rot90(Luna,2))#Sumamos todas las imágenes y componemos:plt.figure(figsize=Dh)plt.imshow(Luna+Luna_rotada180+creciente)plt.title("Luna creciente + Luna1 + Luna1 rotada",size=15)plt.xlabel('pixeles',size=12)plt.ylabel('pixeles',size=12)plt.show()
Bueno, hay algunos detalles de los cuales mejorar en esta composición; como esos puntos blancos sobre la luna creciente que posiblemente están sobre-expuesta dada la combinación de las 3 imagenes. Pero en realidad da igual, programas de edicion de datos como Photoshop o Gimp se especializa en esto y sin tener que saber tanto sobre la composicion, estructura de imágenes, ni de filtros gaussianos, etc.
Pero yo les prometí imágenes astronómicas, además en astronomía/astrofísica, a casi a nadie le importa la luna. Es más, nos cuidamos de su prescensia y apuntamos los telescopios cuando no está para que su terrible luz no opaque los escasos fotones que provienen de nuestras fuentes astronómicas favoritas. Esto es todo lo que tengo que decir con respecto a la luna.
El color de las imágenes astronómicas
Por si no lo sabían, la cantidad de información astronómica disponible en este momento es brutal, onda en el orden de Petabytes de información (1.000.000.000.000.000 bytes) se producen a diario, y en el futuro cercano esta tasa irá al alza, o bueno esa era la proyección antes de la pandemia y la desolación mundial del 2020. Mucha de estas imágenes hecha por telescopios en Tierra y el espacio, como la información que ha sido obtenido a lo largo de su análisis ya es de libre acceso, y algunos sets de datos están especialmente orientados a la divulgación científica, como las históricas imágenes de la Nebulosa del Aguila.
Hechas con la cámara WFPC2 montada en el telescopio espacial Hubble, las imágenes alojadas en la página de la NASA muestran los llamados "Pilares de la creación", las cuales componen parte de la nebulosa del Aguila, y son columnas de polvo desde donde la gravedad hace lo suyo y ensambla nuevas estrellas. Ya el hecho de que tenga nombre propio habla de la popularidad e impacto que tuvo esta imágen alrededor del mundo. Formalmente a este tipo de estructuras se les conoce como "pilares moleculares fríos", como también "*trompas de elefante*".
Estas imágenes están hechas usando filtros de banda estrecha (narrow filters), los cuales se encargan de medir la luz emitida por un elemento en particular, el cual emite radiación en una longuitud de onda específica del rango electromagnético. Las imágenes disponibles están en formato FITS, que es el formato por defecto en la astronomía actualmente.
Entonces, las imágenes disponibles para componer los pilares de la creación son:
Filtro estrecho de Hidrógeno Alfa (H$_\alpha$), la cual posee $\lambda=656$ nanómetros, por supuesto.
Y por ultimo, filtro estrecho de Azufre ionizado (SII), medido a 673 nanómetros
Los elementos anteriores se encuentran presentes en el medio estelar, y son emitidos por la composición e interacción de nebulosas como la que nos interesa. Entonces, descargaremos las imágenes, las leeremos de la misma forma como lo hicimos hace unos momentos más arriba, y luego usaremos la funcion sqrt disponible en astrobetter para ayudar en la visualización de las imágenes:
#Vamos a leer imágenes fits, así que nos preparamosfromastropy.ioimportfitsOxigenoIII=fits.getdata("502nmos.fits")H_alpha=fits.getdata("656nmos.fits")AzufreII=fits.getdata("673nmos.fits")grados=270fz=(6.5,5.8)plt.figure(figsize=fz)rotated_img=ndimage.rotate(AzufreII,grados)plt.title("banda de Azufre II")plt.imshow(rotated_img,cmap='gray',vmin=0,vmax=120)cbar=plt.colorbar()cbar.set_label('cuentas',size=12)plt.ylabel('pixeles',size=12)plt.show()plt.figure(figsize=fz)rotated_img=ndimage.rotate(H_alpha,grados)plt.title(r'banda de Hidrogeno $\alpha$')plt.imshow(rotated_img,cmap='gray',vmin=20,vmax=800)plt.ylabel('pixeles',size=12)cbar=plt.colorbar()cbar.set_label('cuentas',size=12)plt.show()plt.figure(figsize=fz)rotated_img=ndimage.rotate(OxigenoIII,grados)plt.title("banda de Oxigeno III")plt.imshow(rotated_img,cmap='gray',vmin=0,vmax=20)plt.ylabel('pixeles',size=12)plt.xlabel('pixeles',size=12)cbar=plt.colorbar()cbar.set_label('cuentas',size=12)plt.show()
Es posible ver las diferencias, sin dudas (¿verdad?). Por un lado la imagen de AzufreII remarca mucho más los bordes de las nubes, dado que este elemento se encuentra cuando gases a grandes velocidades colisionan. Por otro lado el OxigenoIII y H$_\alpha$ son elementos que se emiten y mapean la materia que está en nuestra querida nebulosa. El OxigenoIII también se ve difuso y marca mucho la absorción de dos de los tres pilares.
Ahora ¿Podemos crear una imágen con estas tres imágenes? Por supuesto, pero será una IMAGEN DE COLOR FALSO. Lo que quiere decir que imágenes realizadas con filtros que no tienen que ver con un color en sí, serán asignados al canal de color para que nuestros ojos puedan entender sus caracteristicas y complejas composiciones fuera de nuestro rango de visión.
Con esto en mente, usaremos python para crear un cubo de datos, y asignaremos cada imagen de filtro estrecho a un canal de color RGB: rojo al mapeo del AzufreII, verde para la emisión de Hidrógeno alfa y el canal azul será para la luz del Oxígeno doblemente ionizado. Con esto, podemos obtener la siguiente imagen.
#Creamos el cubo de datos a la fuerzaimg=np.zeros((AzufreII.shape[0],AzufreII.shape[1],3),dtype=float)#Asignamos cada filtro a un canal: #Silicio al rojo:img[:,:,0]=sqrt(AzufreII,scale_min=0,scale_max=180)#Hidrógeno al verde:img[:,:,1]=sqrt(H_alpha,scale_min=0,scale_max=1200)#Oxígeno al azul:img[:,:,2]=sqrt(OxigenoIII,scale_min=0,scale_max=120)plt.figure(figsize=fz)rotated_img=ndimage.rotate(img,grados)plt.imshow(rotated_img)plt.title(r'{rojo$\rightarrow$SII, verde$\rightarrow$H$_\alpha$, Azul$\rightarrow$OIII}')plt.ylabel('pixeles',size=12)plt.xlabel('pixeles',size=12)plt.show()
Exito!! Estoy contento porque esta es la primera imángen de color falso que compongo :'). Se ve un poco más opaca que la oficial, habría que espejarla con respecto al eje y también, pero estoy conforme. Ahora sabemos cómo los diferentes elementos químicos presentes en los medios interestelares son representados a través de los colores, dándonos las hermosas y abstractas composiciones que el universo tiene para presentarnos.
Ahora, en esos canales de colores es posible poner cualquier imagen hecha con un filtro o escala de grises. Si esto de las bandas aún es un poco confuso, Javiera de Startres lo explica mucho mejor que yo. En su ejemplo, nuestra imagen compuesta correspondería a una imagen realzada.
Cada una de las imágenes a color que muestra la astronomía nos detalla diferentes aspectos de la realidad, muestra elementos complejos que afloran en el centro de las estrellas y emiten los destellos de procesos físicos que pueden llegar a ocurrir en estos ambientes. Cada color puede ser usado para mapear estos efectos, para colorear escalas útiles con el fin de cuantificar interacciones en el medio interestelar; o en general destacar un aspecto diferente de alguna fuente de información en dos dimensiones. Por ejemplo, la siguiente imagen muestra los pilares de la creación (izquierda) compuesta de forma muy similar a cómo nosotros lo hicimos, y a la derecha está compuesta con imágenes de luz infrarroja.
La diferencia es innegable. Ambas conservan la emisión en los bordes de las estructuras, pero la imagen infrarroja muestra incontables estrellas (los puntos brillantes) ¿Por qué? El polvo y las nubes de gas en bajas concentraciones son prácticamente invisibles para la luz infrarroja, por lo que las imágenes hechas en estas bandas nos muestran la luz de estrellas y estructuras escondidas detrás del polvo interestelar, demostrando uno de los grandes problemas de la astronomía: La extinción de la luz.
En mi caso, yo uso imágenes en el rango infrarrojo para así estudiar estrellas detrás de las nubes de polvo que existen en nuestra galaxia: La vía Láctea. El telescopio VISTA vive en el observatorio Paranal, en Antofagasta, y va por la vida recolectando luz infrarroja, invisible para nosotros pero no para la física. Para esto, tomaremos tres imágenes hechas con diferentes filtros desde la base de datos VVV para componer una imagen de color falsa de parte de la nebulosa NGC 6334, también conocida como pata de gato, por las estructuras esferoides que construyeron los vientos de las estrellas brillantes de sus centros.
Pero esas son cosas que uno puede ver en las bandas visibles! El infrarrojo nos ofrece todo lo que está detrás de la patita del gato. Los filtros escogidos para esta tarea son el filtro J, el H, y el Ks. Entonces leeremos las imágenes, las miraremos individualmente y le asignaremos colores raros a cada una de ellas para reforzar que estos colores son sólo un código útil.
fromastropy.ioimportfits#Acomodamos las dimensiones porque siempre falta o sobran píxeles:J1=fits.getdata("J.fits")J=J1[1:,1:]H1=fits.getdata("H.fits")H=H1[1:,:]KS=fits.getdata("Ks.fits")Ks=KS[:,2:]#Separamos cada canal 0,1 y 2 de forma individualf,ejes=plt.subplots(1,3,figsize=(7,7),sharey=True)#Esta la pintamos en escala de grises.ejes[0].imshow(J,cmap='gray',vmin=850,vmax=1000)ejes[0].set_title("Filtro J")ejes[0].set_ylabel("número de pixeles",size=14)#Esta la pintamos con el color por defecto.ejes[1].imshow(H,vmin=2900,vmax=3100)ejes[1].set_title("Filtro H")ejes[1].set_xlabel("número de pixeles",size=18)#Y esta imagen, la pintamos de rojo.ejes[2].imshow(Ks,cmap="Reds",vmin=4200,vmax=4500)ejes[2].set_title("Filtro Ks")plt.tight_layout()plt.show()
Podemos ver algunas estructuras, como así también algunas nubes de polvo y gas que han sido calentadas por las estrellas cercanas a tal materia. Entonces, creamos la imagen de falso color creando el cubo de datos con las tres imágenes anteriores:
Cada uno de los puntitos que vemos es una estrella distinta, y hay incontable número de ellas en una pequeña región del cielo, impactante. Donde está oscuro se localiza las llamadas Nubes oscuras infrarrojas, donde el polvo esta tan concentrado que ni la luz infrarroja puede pasar. Son negras porque no dejan pasar las estrellas que están de fondo, como en todo su alrededor. Las fuentes rojizas representan estrellas que están en su proceso de formación, con unos tiernos cientos de miles de años de vida, y por último, la emisión morado/azulada son nubes que han sido calentadas por sus estrellas calientes a sus alrededores.
Desde el punto de vista astronómico, la Fotometría es la medición, calculo y cuantificación de la luz emitida por diferentes objetos astronómicos. Etimilogicamente, proviene de la voz griega “φωτος” (photos,luz) y del sufijo “μετρια” (metria, medida).
De esta forma, la fotometría es la medición del flujo integrados $F$ (cuentas/tiempo x area) de una fuente en el cielo, y se define matemáticamente de la siguiente forma:
Donde $F_{\lambda}$ es el flujo específico proveniente de la fuente, y $S_{\lambda}$ la función de transmisión, que toma en cuenta la respuesta del detector, la condiciones atmosféricas y el filtro que se ha usado. Lógicamente, y por cómo está planteada la medición, mientras mayor sea el tiempo $t$, mayor flujo integrado se obtiene.
Magnitudes y flujos
La magnitud astronómica es, por definición, una cantidad relativa. Esto quiere decir que su valor es definido con respecto a una fuente específica (como por ejemplo, el sistema fotométrico basado en la estrellas Vega). Dos variaciones populares de la magnitud astronomómica son las siguientes:
Entonce, necesitamos los Flujos de, al menos, dos estrellas relativamente cercana. Hay tres métodos principales para medir dicho flujo $F$:
Fotometría de apertura.
Fotometría diferencial.
Fotometría de función de dispersión de punto, o point-spread-function (PSF).
Cada una de estas técnicas posee diferentes filosofías, ventajas y desventas, pero todos tienen en común algunos parámetros. Partamos con la primera:
Fotometría de apertura
Esta técnica se basa en considerar todas las cuentas (ADU) dentro de un radio $R$ definido, el cual es llamado "apertura", teniendo como regla que el radio de apertura debe ser, a lo menos, menor que el seeing $R<seeing$ (visión o visibilidad astronómica).
Hay que recordar que una imagen (astronómica, fotográfica, etc) es un arreglo de datos de $(n \times n)$ píxeles, entonces los valores $I_{ij}$ describiran las coordenadas físicas de la imagen. Naturalmente, el flujo de luz proveniente de una fuente estelar, por un tiempo de antemano conocido, puede ser estimado sumando cada pixel $I_{ij}$ dentro de la circunferencia caracterizada por el radio R. En palabras más precisas, dentro de la apertura.
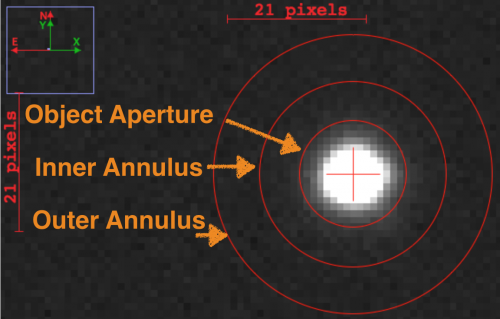
Luego, debemos sustraer la contribución del cielo a la medición usando alguna estimación directa del valor de "cielo". Podemos pensar en esta contribución como el ruido de fondo de la imagen, y será cuantificado como el valor promedio de una imagen en lugares donde no existen objetos astronómicos. Para estimar el cielo, se define una región llamada "Annulus", que es una estructura creada con dos circulos que posee forma de donut. La idea es medir la contribución local (el área circundante) de la imagen para obtener el flujo usando algún estadístico, digamos, el promedio.
La Figura 1 representa de mejor manera este concepto. Por ejemplo, medimos todos los píxeles $I_{ij}$ dentro del radio interior (Inner Annulus marcado en la imagen) y el exterior (Outer Annulus), obtenemos un valor promedio y será considerado el cielo.
Figura 1: Geometría relacionada a la fotometría de apertura.
Bajo esta interpretación, el número total de cuentas $I$ dentro del radio de apertura $R$ será la suma de cada uno de los píxeles $I_{ij}$ de la imagen dentro del radio R considerado, menos la contribución del cielo $I_{cielo}$ en cada píxel:
$$
I=\sum_{i,j} I_{ij} - n_{pixeles}*I_{cielo}
$$
donde:
$I$: Cuentas totales de la fuente dentro del radio de apertura.
$I_{ij}$: Cuentas específicas en cada pixel dentro del radio de apertura.
$n_{pixeles}$: Número de píxeles dentro de la apertura.
$I_{cielo}$: Valor de la contribución estimada del cielo usando el annulus. Usualmente es llamado 'Cielo'.
Generalmente, el valor del cielo se obtiene desde la distribución del número de cuentas dentro de la imagen.
Finalmente, la magnitud instrumental viene dado por:
$$
m=-2.5\log_{10}(I) + Constante
$$
El termino constante depende de las variables asociadas a las condiciones de observación (por ejemplo la extincion atmosferica, la masa de aire, el seeing), y básicamente es lo que se modifica para poder calibrar la fotometría en cierca escala de interés.
La gran desventaja de este método es la alta densidad estelar. No es posible usar fotometría de apertura cuando la fuente bajo estudio no está aislada, que es el caso de grupos de estrellas como los Cúmulos globulares, o en el centro de nuestra galaxia. De alguna forma, el veloz avance de la resolución espacial de las nuevas generaciones de telescopios ha demostrado que la fotometría de apertura es la primera aproximación a la medición del flujo estelar (o gáctico).
Fotometría Diferencial
La fotometría diferencial consiste en usar estrellas de comparación dentro de la misma imagen para estudiar una estrella en particular, y así ignorar hasta cierto punto las variables atmosféricas y el tiempo de integración. Este método está enfocado en cuantificar la variabilidad estelar de la fuente de interés, y para ser implementada es necesario elegir unas 4 o 10 estrellas de comparación C, medir su magnitud instrumental $m_C$ a través de varias observaciones (o épocas) y calcular el diferencial de magnitud $\Delta m_C$ de cada estrela de comparación, con el fin de cuantificar el cambio de brillo de la estrella de interés.
Este método ofrece muy buenos resultados cuando la cadencia de observación es alta, siendo uno de los favoritos del AAVSO, Kepler, entre otros, pero desconozco si es un método que se siga usando de forma masiva, pero es una interesante forma de medir la luz de las estrellas.
Fotometría PSF
Este método se basa en la idea que todas las fuentes en una imagen tienen exactamente la misma forma. En otras palabras, la distribución espacial de la luz capturada sobre una imagen sigue alguna regla general, que puede ser usada para estimar el flujo F.
PSF es un acrónimo en ingles Point spread functionLa aproximación más usual es asumir que las fuentes poseen un perfil Gaussiano con la misma desviación estándar. Con esta aproximación, el "tamaño" o apertura para una fuente estará caracterizada por el seeing atmosférico. Dependiendo del tamaño de la imagen en la cual trabajemos, podemos considerar que tenemos, en promedio, las mismas perturbaciones atmosféricas. Bajo estas consideraciones, todas las estrellas deberían ser descritas por la misma función puntual de dispersión (point spread function, PSF).
La forma radial de una Gaussiana bidimensional se describe como:
$I(r)$ Es la intensidad para algún pixel de coordenadas $(x,y)$.
$r=\sqrt{x^2+y^2}$ es la componente radial de una Gaussiana 2-D.
$I_{0}$ Es el peak de intensidad del perfil.
$\sigma$ Es la desviación estándar del perfil (el ancho del perfil Gaussiano).
La simpleza y utilidad de la fotometría PSF recae en que todas las estrellas pueden ser modeladas usando, en este caso, un perfil Gaussiano con la misma desviación estándar (seeing) $\sigma$, y cada una con diferentes intensidades $I_0$, lo que reduce el problema a elegir un set de parámetros para cada imagen a analizar.
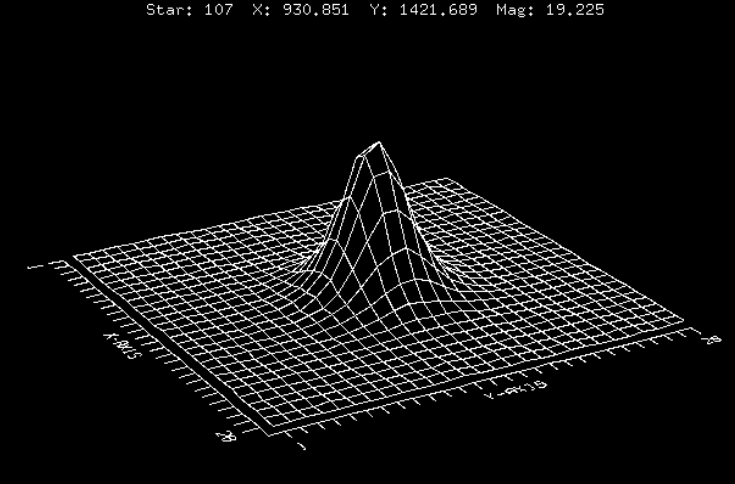
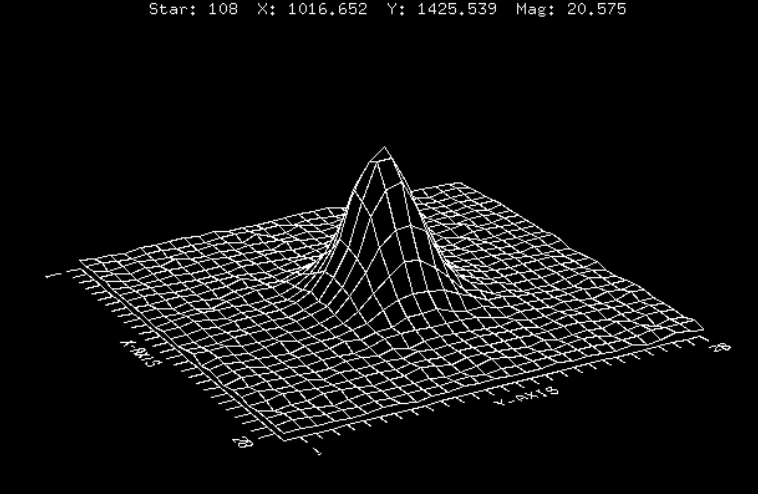
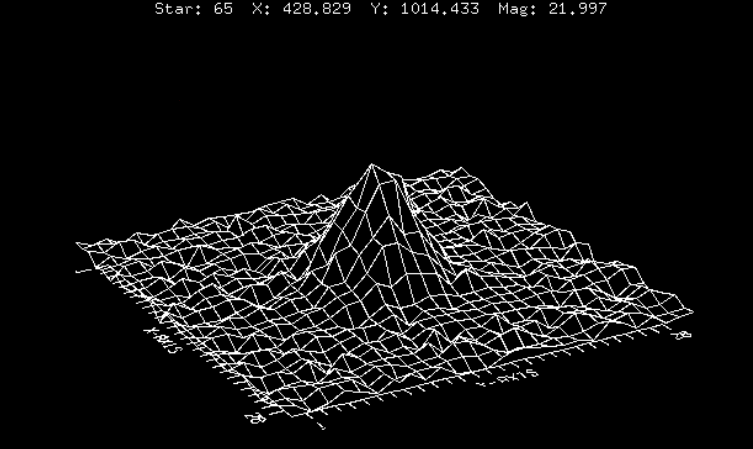
A continuación, se presentan 3 estrellas de diferentes magnitudes, pero que presentan la misma forma:
Fig 2: Perfiles de distribución de la luz estelar en diferentes intensidades. El ruido cada vez es más importante. Las estrellas tiene, de arriba a abajo, magnitud 19.225, magnitud 20.575, y magnitud 21.997.
¿Cuál es la diferencia? La forma de la fuente se mantiene, pero el nivel de ruido del fondo crece. En general, si el peak de intensidad $I_0$ está por sobre el límite del ruido, podrá ser detectada y analizada.
Para entender mejor la idea, simularemos una estrella usando una distribución gaussiana y estudiaremos sus parámetros con más detalles. Le añadiremos ruido para hacer todo un poco más realista.
#Agregamos las librerias fundamentales para trabajar.%matplotlib inline
importmatplotlib.pyplotaspltimportmatplotlib.cmascmimportnumpyasnpimportosimportsys#Creamos el dominio:Rango_imagen=100numero_filas=100numero_columnas=100x=np.linspace(-Rango_imagen,Rango_imagen,numero_columnas)y=np.linspace(-Rango_imagen,Rango_imagen,numero_filas)X,Y=np.meshgrid(x,y)#calculo de la intensidadr0=0#Desplazamientosigma=20.#Desviación estándar.I0=1000.#Peack de intensidad.R=np.sqrt((X-r0)**2+(Y-r0)**2)#Componente radial.#Calculamos el Perfil.Perfil=I0*np.exp(-0.5*(R/sigma)**2)#Simulamos ruido que emule la contribución de fondo:Valor_piso=100.desviacion_estandar_ruido=150Dimension_imagen=Perfil.shapebackground=np.random.normal(Valor_piso,desviacion_estandar_ruido,Dimension_imagen)#componemos todo:Perfil_ruido=Perfil+background#Hacemos el plot:plt.figure(figsize=(12,6))plt.subplot(121)plt.title('Perfil Gaussiano')plt.imshow(Perfil,cmap=cm.jet)plt.colorbar(orientation='vertical',fraction=0.046)plt.xlabel('pixel X',fontsize=15)plt.ylabel('pixel Y',fontsize=15)plt.subplot(122)plt.title('Perfil Gaussiano con ruido')plt.imshow(Perfil_ruido,cmap=cm.jet)cbar=plt.colorbar(orientation='vertical',fraction=0.046)cbar.ax.get_yaxis().labelpad=20cbar.ax.set_ylabel('Intensidad $I_0$',rotation=270,fontsize=15)plt.xlabel('pixel X',fontsize=15)plt.show()
A la izquierda de la imagen, se puede ver lo que puede ser describido como la simulación de un objeto astronómico usando una distribución espacial gaussiana. El mapa de colores describe su inconfundible perfil. A la derecha, la misma imagen con la fuente simulada, pero ha sido agregado una componente de ruido de fondo también generado usando una distribución normal o gaussiana.
Hagamos cortes transversales en dos fuentes generadas con diferente intensidad $I$ y el mismo seeing $\sigma$ para poder visualizar los cambios y efectos del ruido.
#Creamos dos perfiles con la misma desviación estándar y diferente intensidad:centro_imagen=len(X[:,0])/2I1=I0I2=2700.#Peack de intensidad.#Creamos un segundo perfil para comparar:Perfil_2=I2*np.exp(-0.5*(R/sigma)**2)#Simulamos (otro) ruido que emule la contribución de fondo:background=np.random.normal(Valor_piso,desviacion_estandar_ruido,Dimension_imagen)#componemos el segundo perfil:Perfil_ruido_2=Perfil_2+backgroundplt.figure(figsize=(10,7))plt.plot(X[centro_imagen],Perfil_ruido[centro_imagen],'ro',ms=7,label='$I_1 = %1.0f$'%I1)
plt.plot(X[centro_imagen],Perfil_ruido_2[centro_imagen],'kH',ms=6,label='$I_2 = %1.0f$'%I2)
plt.xlabel('pixel X',fontsize=15)plt.ylabel(r'Intensidad',fontsize=15)plt.plot([min(X[centro_imagen]),max(X[centro_imagen])],Valor_piso*np.ones(2),'g-',lw=4,label="Piso constante")plt.legend(fontsize=15)plt.show()
En ambos casos, el perfil gaussiano se mantiene a pesar del ruido, pero la menos intensa se ve mayormente perjudicada por contribuciones de fondo. En ambos casos, el brillo de las fuentes será proporcional al flujo contendio bajo esta Gaussiana. Así, podemos describir la diferencia de magnitud entre dos fuentes de la siguiente forma:
Así, en vez de contar fotones y restar la contribución de fondo, sólo necesitamos encontrar el perfil que ajusta de mejor manera a $I(r)$, esto nos dará el valor del peak espefícico $I$. Y así, es posible calcular la magnitud instrumental $m$ de la forma:
$$
m = -2.5 \log(I_0) + const.
$$
Donde la constante está dada por el sistema fotométrico utilizado (es decir, el punto cero).
Ventajas de la fotometría PSF
Precisión: Como ya hemos comentado, la fotometría de apertura suma todos los píxeles dentro de una apertura arbitraria. Si alguno de estos píxeles es un pixel caliente, un rayo cósmico u otro, podría aumentar drásticamente el valor de la medición fotométrica. El ajuste de un perfil para obtener el valor $I_0$ convierte a la fotometría PSF en un estimador robusto a píxeles malos, rayos cósmicos y otros contaminantes.
Puede ser usado en campos muy poblados: Como sabemos la forma que debe tener cada estrella, podemos estimar el flujo que debe aportar cada fuente al estudiar regiones de alta densidad estelar, como cúmulos globulares o el centro galáctico. Podemos aplicar iterativamente perfiles sobre fuentes para remover contribuciones con el fin de caracterizar de mejor manera estas fuentes que se solapan.
Otros perfiles que pueden ser usados
Usualmente, dependiendo de las condiciones ambientales o de las fuentes en estudio, se pueden usar diferentes perfiles para describir las fuentes. A modo de ejemplo, presentamos algunos de ellos:
Perfil de Moffat:
$$
\displaystyle M(r) = \frac{1}{\left[1+\left(\frac{r}{\sigma}\right)^2\right]^b}
$$
Donde b es un parámetro libre que se ajustan para obtener la contribución del brillo de la fuente.
Realizando Fotometría PSF
Existen varias formas de obtener la fotometría PSF desde imágenes astronómicas. Generalmente cada survey ofrece entre su documentación cuál es la tecnica fotométrica que sugieren, el software y sus posibles limitancias. Algunos softwares populares y (que yo personalmente he usado) son los siguientes:
DAOPHOT: Extractor de fuentes clásico, muy usado en el software IRAF en tiempos tempranos, donde se realizaba la calibración de objetos a mano. Disponible en paquetes de utilidades astronómicas y distribuido generalizadamente.
DoPHOT: Segun uno de los autores, uno de los softwares más usados que provee diferentes modalidades de extracción de fuentes. Doy completa fe de su reputación.
SexTractor: El peor acrónimo del mundo, estamos de acuerdo. Software muy mañoso en su instalación, pero efectivo para obtener catálogos de fotometría sobre una imagen FITS.
Ahora, veremos un ejemplo (y explicación) sobre cómo simular una fuente y realizarle fotometría usando algunas librerias implementadas en python. Más información disponible en la documentacio del siguiente link.
Vamos describiendo cada paso y modificando a nuestras anchas a ve qué sucede:
#Importamos todas las librerías necesarias para nuestro propósito:fromphotutils.detectionimportIRAFStarFinderfromphotutils.psfimportIntegratedGaussianPRF,DAOGroupfromphotutils.backgroundimportMMMBackground,MADStdBackgroundRMSfromastropy.modeling.fittingimportLevMarLSQFitterfromastropy.statsimportgaussian_sigma_to_fwhmfromastropy.tableimportTablefromphotutils.datasetsimport(make_random_gaussians_table,make_noise_image,make_gaussian_sources_image)#Ajustamos algunos valores para empezarsigma_psf=3.0tshape=(32,32)#Dimensiones de la imagensources=Table()#crea una tabla para mapear los parametros de 3 fuentessources['flux']=[700,1900,1000]sources['x_mean']=[14,16,16]sources['y_mean']=[15,15,17]sources['x_stddev']=sigma_psf*np.ones(3)sources['y_stddev']=sources['x_stddev']sources['theta']=[0,0,0]sources['id']=[1,2,4]#Crea la imagen, que será la suma de 3 fuentes, #y agregando ruido basado en una distribución de Poisson# y ruido normal:image=(make_gaussian_sources_image(tshape,sources)+make_noise_image(tshape,type='poisson',mean=8.,random_state=1)+make_noise_image(tshape,type='gaussian',mean=0.,stddev=5.,random_state=1))#ploteamos la imagen resultante:plt.figure(figsize=(5,6))plt.imshow(image,cmap='viridis',aspect=1,interpolation='nearest')plt.title('Imagen simulada')plt.colorbar(orientation='vertical',fraction=0.046,pad=0.04)plt.show()
#importamos más funciones especificas:fromphotutils.detectionimportIRAFStarFinderfromphotutils.psfimportIntegratedGaussianPRF,DAOGroupfromphotutils.backgroundimportMMMBackground,MADStdBackgroundRMSfromastropy.modeling.fittingimportLevMarLSQFitterfromastropy.statsimportgaussian_sigma_to_fwhmfromphotutils.psfimportIterativelySubtractedPSFPhotometry#Medimos el cielo usando el estadistico MAD:bkgrms=MADStdBackgroundRMS()#usamos la imagen creada como dato de entrada:std=bkgrms(image)#Método para encontrar iterativamente fuentes en la imagen.iraffind=IRAFStarFinder(threshold=3.5*std, \
fwhm=sigma_psf*gaussian_sigma_to_fwhm, \
minsep_fwhm=0.01,roundhi=5.0,roundlo=-5.0, \
sharplo=0.0,sharphi=2.0)daogroup=DAOGroup(2.0*sigma_psf*gaussian_sigma_to_fwhm)#estimamos la contribucion del cielo (background):mmm_bkg=MMMBackground()#eligen el modelo PSF:psf_model=IntegratedGaussianPRF(sigma=sigma_psf)#Creamos el modelo a aplicar en nuestra imagen:photometry=IterativelySubtractedPSFPhotometry(finder=iraffind,group_maker=daogroup,bkg_estimator=mmm_bkg,psf_model=psf_model,niters=1,fitshape=(11,11))#Realizamos la fotometría:resultados=photometry(image=image)#revisamos los parámetros principales de la fotometría, el flujo:list(result_tab)
El programa ha estimado el centroide (x_fit,y_fit) la fuente extraida, el que está localizado (con respecto a la imagen creada) en (X,Y)= (15.489, 15.775), y que posee un flujo = 2320.57 unidades arbitrarias. Como hemos superpuesto 3 fuentes con intensidades de 700, 1900, 1000, me hace mucho sentido que el programa extraiga una sola fuente con un flujo cercano a la superposición de las tres fuentes.
Las piezas de código que hemos explorado anteriormente están llenas de secretos, sorpresas y demases. Por ejemplo, a partir del modelo aplicado es posible literalmente extraer la fuente de la imagen, creando un mapa residual que se crea restando el modelo con la imagen. Veamos:
#obtenemos la imagen residual de la ejecución anterior.residual_image=photometry.get_residual_image()plt.figure(figsize=(9,6))plt.subplot(121)plt.imshow(image,cmap='viridis',aspect=1,interpolation='nearest')plt.title('Imagen simulada')plt.subplot(122)plt.imshow(residual_image,cmap='viridis',aspect=1,interpolation='nearest',origin='lower')plt.title('Imagen residual')plt.show()
Esto puede ser muy útil para estudiar fuentes astronómicas que están demasiado cerca de una fuente brillante, como es el caso de los exoplanetas. Una idea que lleva directamente al coronógrafo.
Por último, voy a poner una imagen real y hacerle fotometría, pero me queda como trabajo futuro.
En el 2017, un objeto extraño y sin precedentes fue ubicado por el telescopio Pan-STARRS (localizado en Hawaii) entre las miles de millones de fuentes estelares que habitan en nuestra galaxia. En el momento del hallazgo, esta cuerpo fue catalogado premilimarmente como un cometa, dado que cumplía alguno de los parámetros esperados para este tipo de objetos celestes; pero luego de la revisión rutinaria se empezaron a develar las exóticas propiedades de este cuerpo: Su brillo cambiaba a lo largo del tiempo, una velocidad abrumadora y una trayectoria completamente inusual, tal que no parecía orbitar nuestro sol en absoluto. Por toda la expectación que esto generó, el objeto en cuestión tenía más un perfil de ser un asteroide, y fue bautizado "Oumuamua", que significa "Explorador" en Hawaiano.
Un objeto fuera del sistema solar.
La velocidad y trayectoria con la que Oumuamua atravesaba el sistema solar (velocidad estimada de 315.431 $\frac{Km}{hora}$ en su punto más cercano al sol [1]) sugería que no poseía una ligadura gravitacional a nuestro sistema solar, por lo que debía provenir desde otro sistema estelar ajeno al nuestro, algo sin precedentes hasta la fecha. Además, al terminar la visita de nuestro vecindario cósmico, Oumuamua seguiría su trayectoria a lo largo de el espacio interestelar, tomando un nuevo rumbo gracias a modificación de la trayectoria causada por la cercanía a nuestra estrella huésped.
El siguiente video ilustra la trayectoria calculada del misterioso objeto, y se compara con el movimiento observado. También es posible ver la dirección desde dónde provino y hacia dónde fue.
Pero eso no lo es todo, había otro dato observacional del cual podía extraerse información valiosa: El asteroide poseía una fluctuación periódica de su brillo superficial, es decir, que su luz cambiaba siguiendo un ciclo aparentemente definido, algo que es propio de las estrellas y cuerpos suficientemente energéticos para producir luz propia. Como un objeto de esta clase no posee las condiciones mínimas para generar reacciones nucleares en su interior, la variabilidad de su brillo debe producirse por otro tipo de características, como la forma del mismo.
Un asteroide con forma...¿de cigarro?
Para internarse en el problema de su brillo, observaciones de diferentes telescopios fueron combinadas para dar claridad en los detalles. Varios equipos de astrónomos usaron estos datos y encontraron periodo de fluctuación de brillo de este "explorador" era de algunas horas (entre 6.9 a 8.3 horas)[2], lo que podía explicarse si es que el asteroide estuviera girando sobre si mismo en una especie de tambaleo. Una de las consecuencias de esa afirmación, es que Oumuamua poseía una forma preferentemente cilíndrica y alargada, con algunos cientos de metros de largo. Una forma como la señalada es enormemente inusual para un asteroide.
El hecho de sugerir esta forma, y dados todos los otros detalles antes señalados, encendió rápidamente las alarmas y la imaginación, dado que anteriormente equipos de trabajo que han desarrollado investigación en transporte espacial de largas distancias habían sugerido que la forma de aguja o "cigarro" era la más adecuada para una nave interestelar, dado que la geometría minimizaría la fricción y daños provocados por el polvo, gas u otras estructuras interestelares. Esta geometría para una nave es tan intuitiva que se ve reflejada en las naves espaciales de algunas sagas de ciencia ficción. Muchas comparaciones fueron hechas, y acá hay un ejemplo de esto.
Con todo esto en mente, la primera impresión que uno podría tener de Oumuamua se refleja en la Figura 1.
fromIPython.displayimportImageprint'Figura 1: Primera ilustración artistica de lo que sería el visitante Oumuamua.'Image(url="http://s3.amazonaws.com/ogden_images/www.mauinews.com/images/2017/12/07060907/intersellar-object.jpg",width=500)
Figura 1: Primera ilustración artistica de lo que sería el visitante Oumuamua.
Aún así, debemos considerar que la posibilidad de que un objeto tenga una forma inusual, como por ejemplo la luna "Pan" de Saturno, que posee la peculiar forma de un 'ravioli' (Figura 2) no es desestimable. Varios astrónomos han señalado diferentes escenarios donde se podría obtener estas particulares formas, como la colisión de dos o más asteroides. Aún así, la idea de que pudiera ser un artefacto alienigena es atractiva y, por ende, difícil de quitar del imaginario colectivo.
print'Figura 2: Pan, el ravioli que orbita el planeta Saturno. \Las imágenes fueron tomadas por la sonda Cassini en 2017.'Image(url="https://fotografias.lasexta.com/clipping/cmsimages02/2017/03/10/25398870-BA11-4C6B-8423-44F663DDB8BA/58.jpg",width=350)
Figura 2: Pan, el ravioli que orbita el planeta Saturno. Las imágenes fueron tomadas por la sonda Cassini en 2017.
Sin embargo, nada más en en sistema solar se ve de esta forma alargada cilíndrica, y mientras pasaban los días, más astrónomos reportaban diferentes periodos de cambio de luminosidad, lo que podía sugerir que si estaba efectivamente rotando sobre un eje, quizá había más de un eje de rotación[3], lo que producía un periodo más caótico. El hecho de asumir más de un eje de rotación nos conduce a volver a pensar cómo sería la forma de Oumuamua, y se piensa que la siguiente representación artística sea más acertada:
print'Figura 3: Versión más probable de la forma de Oumuamua.'Image(url="https://cdnnoticiasecatepec-ncq7dy8l5rwi43a.stackpathdns.com/wp-content/uploads/2018/11/Oumuamua-painting-Hartmann.jpg",width=500)
Figura 3: Versión más probable de la forma de Oumuamua.
Buen viaje, Oumuamua.
En septiembre del 2017, el asteroide pasó por su punto más cercano al Sol, pasando por dentro de la órbita de Mercurio; y emprendió el viaje de retirada hacia otros horizontes de la galaxia. En enero de este año (2019) el asteroide ya sobrepasó la órbita de Saturno, y le tomará otros varios miles de años para escapar completamente del sistema solar. En su corta estadía en la parte interna de nuestro pequeño sistema planetario, Oumuamua ha dejado muchas más dudas que certidumbre, iluminando nuevamente los ojos de aquellos que buscan evidencia de vida extraterrestre. Aunque gran parte de su fenomenología ha conseguido ser explicada a través de fenómenos físicos que han sido observados en otros cuerpos, Oumuamua es un objeto asombroso y único en su especie, por lo que quedamos con la expectativa de que otro objeto similar pueda ser visualizado en una época temprana para su completo estudio, entendimiento y caracterización.
Hace bastante tiempo quería explicar el por qué creo que programar es importante como una manera de estructurar e implementar el pensamiento lógico. Comprender sus aplicaciones nos habilita a entender diferentes aspectos de nuestra realidad. Con sus herramientas uno podría, por sólo dar ejemplos, construir y reproducir experimentos científicos, estudiar bases de datos para llegar a conclusiones y exhibirlas de una manera comprensible.
Dominar en algún nivel sus herramienta es fundamental en la actualidad, no sólo para las personas relacionadas a la ciencias e ingeniería sino también para aquellos que se interesan en la búsqueda, visualización e interpretación de diversas bases de datos, como periodistas y/o psicólogos.
Creo que al adquirir el punto de vista de la implementación y flujo de cálculos matemáticos, tomé perspectiva del potencial de programar un sistema. Además si nos ponemos románticos, podríamos decir que programar es como crear un pequeño mundo, el cual sigue las reglas asignadas por el escritor sin excepción alguna.
Gran parte de estas técnicas de análisis se desarrollaron originalmente usando lógica y cálculos matemáticos complejos, los cuales fueron potenciados con la aparición de computadores capaces de optimizar operaciones, automatizar procesos y realizar cálculos sostenidos a través del tiempo. Hoy en día, el acceso a este tipo de análisis es bastante transversal en comparación al siglo pasado, básicamente es necesario una computadora personal o smartphone, acceso a internet, los datos a analizar y simpatía por el idioma inglés.
Hay toda clase de tutoriales en internet con los cuales uno puede aprender de manera autodidacta sobre variadas temáticas, lenguajes de programación y futuras aplicaciones. Yo aquí recolectaré y daré un espacio a lo interesante que todo esto podría llegar a ser.
Como sistema de comunicación, la lógica computacional puede ser descrita y comunicada a través de diferentes idiomas, los cuales son denominados lenguajes de programación. El criterio para elegir uno de ellos pueden ser variados, como la velocidad de ejecución u entorno de desarrollo.
Python es un lenguaje apropiado para aprender de cero a implementar código de manera simple, ya que posee una sintaxis simple y directa lo que conlleva una fácil interpretación para el usuario. Varías estadísticas revelan que Python ha crecido exponencialmente en términos de usuarios en los últimos años. Esto alienta a la creación de librerías especializadas y de carácter libre.
El sistema de Lorenz es un set de ecuaciones diferenciales acopladas las cuales tiene soluciones caóticas dados ciertos parámetros $\sigma$, $\rho$ y $\beta$ con las condiciones iniciales $x(0)$, $y(0)$ y $z(0)$ evaluadas en la posición inicial de nuestra partícula P.
El truco acá será discretizar los diferenciales del set de ecuaciones, asumiendo que el infinitesimal temporal ${\rm d}t$ puede ser aproximada usando una diferencia finita $\Delta t$ suficientemente pequeña. Lo mismo será asumido para las variables espaciales, así por ejemplo para la variable i-ésima $x_{i}$, tenemos que $\Delta x_{i+1} = x_{i+1} - x_{i}$.
Dicho esto, nuestras ecuaciones toman la siguiente forma:
Así, pondremos una partícula de prueba en este mundo gobernado por estas tres leyes y evaluaremos su comportamiento usando 50 mil pequeños pasos $\Delta t$ para ver cómo evoluciona a través de 50 segundos.
No se diga más!
In [1]:
#Importamos las librerías que nos harán la vida fácil :)%matplotlib inline
importnumpyasnpimportmatplotlib.pyplotaspltfrommpl_toolkits.mplot3dimportAxes3Dfrommpl_toolkits.basemapimportBasemapimportpandasaspd
In [3]:
#Valores usuales para los parámetros de Lorenz sigma,beta,rho=10,2.667,28#Número de puntos a evaluarnpuntos=50000#Paso de tiempo:dt=0.001#iniciamos vectores:x=np.zeros(npuntos)y=np.zeros(npuntos)z=np.zeros(npuntos)t=np.zeros(npuntos)inicio_particula=(30,0,10)x[0],y[0],z[0]=inicio_particula#Aplicamos las leyes establecidas:foriinrange(npuntos-1):x[i+1]=x[i]+sigma*(y[i]-x[i])*dty[i+1]=y[i]+(rho*x[i]-z[i]*x[i]-y[i])*dtz[i+1]=z[i]+(x[i]*y[i]-beta*z[i])*dtt[i+1]=t[i]+dt#Empieza el plot:plt.figure(figsize=(10,4))fz=18axes=15plt.subplot(311)plt.plot(t,x,'b')plt.ylabel('Variable x')plt.subplot(312)plt.plot(t,y,'k')plt.ylabel('Variable y')plt.subplot(313)plt.plot(t,z,'c')plt.xlabel('Tiempo [segundos]',fontsize=axes)plt.ylabel('Variable z')plt.tight_layout()plt.show()#Ploteamos el Atractor de Lorenz:fig=plt.figure(figsize=(15,8))ax=fig.gca(projection='3d')#Pintamos la trayectoria de la particula de prueba:segmentos=1000c=np.linspace(0,1,npuntos)foriinrange(0,npuntos-segmentos,segmentos):paso=i+segmentosax.plot(x[i:paso],y[i:paso],z[i:paso],color=(0,c[i],0),alpha=0.8)#Punto de inicio:ax.scatter(inicio_particula[0],inicio_particula[1],inicio_particula[2],'o',color='red')ax.set_axis_off()ax.set_title("El atractor de Lorenz",fontsize=fz)plt.show()
Entonces, la partícula roja se ha desplazado acorde a las leyes de Lorenz, y ha trazado el comportamiento característico de este set de ecuaciones diferenciales, y por lo cual es frecuentemente llamado el Atractor de Lorenz. El comportamiento individual de cada variable a través del tiempo puede ser consultado en los gráficos en la parte superior.
Si vives en Chile, probablemente te habrás dado cuenta que es un país muy sísmico. Tan solo en ésta década hemos tenidos varios terremotos con una magnitud sobre 7 en escala de magnitud local. Cada vez que hay un temblor, los memes vuelan e imploran que se presente Marcelo Lagos a dar el reporte, y hasta un trago se llama Terremoto. Entonces: ¿será verdad que en otras partes del mundo, esto de los sismos no es normal?
Esta pregunta podría ser resuelta si es que visualizamos cada evento registrado desde alguna fecha arbitraria y ver cómo estos se localizan a través de Sudamérica. Para saber esto, hemos consultado la base de datos de la pagina de monitoreo sismológico de la Universidad de Chile, entre los años 2003 y 2015, obteniendo una lista con más de 58 mil sismos distribuidos a lo largo del continente.
Estos datos han sido recolectados en este post (usando otro lenguaje de programación :p) y crearemos un mapa con la distribución de sismos en Sudamérica entre el 2003 y 2015.
Así nomás.
In [8]:
#Leemos el archivo con los sismosdata=pd.read_csv("sismos.csv")#Vemos qué es lo que dicen las primeras lineas printdata.head()
Fecha localFecha UTC Unnamed: 1 Latitud Longitud Profundidad_Km \
0 1/1/2003 16:26 1/1/2003 19:26 -34.710 -70.174 0.0
1 1/1/2003 14:22 1/1/2003 17:22 -35.112 -71.375 63.1
2 1/1/2003 14:02 1/1/2003 17:02 -31.051 -71.310 64.4
3 1/1/2003 13:25 1/1/2003 16:25 -30.159 -70.141 5.4
4 1/1/2003 12:54 1/1/2003 15:54 -32.138 -71.753 11.0
Magnitud Referencia
0 3.1 Mc GUC 76 km al E de San Fernando
1 2.9 Mc GUC3.1 Ml GUC 44 km al NE de Talca
2 2.9 Mc GUC2.5 Ml GUC 33 km al NO de Combarbalá
3 3.3 Mc GUC2.7 Ml GUC 57 km al E de Vicuña
4 3.6 Mc GUC3.3 Ml GUC 60 km al NO de La Ligua
In [9]:
#Entendemos el archivo y le damos el formato adecuado para hacer los gráficosLatitudes=data['Latitud'].valuesLongitudes=data['Longitud'].valuesProfundidades=data['Profundidad_Km'].valuesMagnitudes=data['Magnitud'].values#Damos el formato a las magnitudes, esto es lo más fome así que ignórenlo.Mag=np.array([Magnitudes[i].split()[0]foriinrange(len(Magnitudes))])Mags=np.zeros(len(Mag))foriinrange(len(Mag)):ifMag[i]=="''":Mags[i]=0else:Mags[i]=float(Mag[i])
In [11]:
#Límites de latitud:x1=-90.x2=-25.#Límites de longuitud:y1=-56.y2=17.m=Basemap(resolution='h',projection='merc',llcrnrlat=y1,urcrnrlat=y2,llcrnrlon=x1,urcrnrlon=x2,lat_ts=(x1+x2)/2.)plt.figure(figsize=(8,13))#Lineas fronterizas de los paísesm.drawcoastlines(linewidth=1)m.drawcountries(linewidth=1)#Color del mapa del fondo:m.bluemarble()#Meridianos y paralelos:m.drawmeridians(np.arange(0,360,10),labels=[False,True,True,False])m.drawparallels(np.arange(-90,90,10),labels=[False,True,True,False])#Mapeamos las coordenadas:x,y=m(Longitudes,Latitudes)m.scatter(x,y,s=np.exp(Mags),c=Profundidades,alpha=0.7,edgecolors='black',linewidth=0.45)cbar=plt.colorbar(orientation='horizontal',pad=0.01)cbar.set_label(r'${\rm Profundidad\ [Km]}$',size=20)#Creamos la escala para las magnitudes, recordando que la escala es logaritmica:forain[55,250,1100]:plt.scatter([],[],c='k',alpha=1,s=a,label=str(round(np.log(a),1))+' Mc GUC')plt.legend(scatterpoints=1,frameon=True,labelspacing=2,loc='lower right');plt.tight_layout()plt.show()
Con todo esto, podemos ver que 8 de cada 10 sismos, prefieren Chile :p
Esto es sólo una muestra de todo lo que es posible hacer cuando tienes datos disponibles, herramientas para su análisis, y tiempo para aprender.
Hola mundo! Desde hoy empezaré a escribir en este espacio, así que les doy la bienvenida!
La verdad, aún no tengo claro sobre qué tratará este espacio, pero imagino que me enfocaré en escribir sobre ciencia, sobre mi trabajo como astrónomo; sobre física, programación, quizá música o cualquier otro tema que pueda ser relevante.
He decidido crear este blog dada la inmensa cantidad de información que he podido aprender a través de internet en todos estos años, sobretodo cuando empecé a realizar mi magíster, y que he ido madurando a lo largo de mi doctorado. Por lo tanto, siento que es un deber contribuir algo que pueda ser de utilidad para alguna persona curiosa.
Dicha esta declaración de principios, nos estamos leyendo!







.png)

























{kind=link}